前言。本文作于GCN横空出世(2017)的三年后(2020),想尽可能在简单易懂的情况下说清楚近年GNN的发展脉络。当然,凭我鸽子王的尿性,估计本来也就不会写的很翔实(简单是第一层,偷懒是第二层🐶)。
4th, March, 2021. Update: After a series of rejections by AI conferences, I note that I may look back on these papers and rethink why these papers can be accepted, i.e., review them in a positive and admired way instead of criticising them. Also, I try to pay attentions to the authors and institutes, and summarize the research style of different groups. This helps to understand the whole GNN community and “may” contribute to my PhD dicision.
最近GNN又看了一些ICLR2020的paper,加之之前积累的paper,对整个GNN的发展脉络有了比较清楚的理解,之所以想要记录在案,是因为发现:
- GNN有点类似CNN,是一个入门难度不高,效果又比较出色的技术。不像EDA里面各种子问题及现在的SOTA解决方案,要解释清楚就要半天。
- 现在的各种文章因为作者们的严谨及数学功底的雄厚,导致涉及内容过多,我要真正看明白的阈值太高(对不起实在是因为我太菜了),因此心里琢磨着要是能有一篇浅显易懂的综述,快捷的理清paper间的区别和发展脉络该多好。
- 现在许多GNN的paper其实真正technique部分的contribution很容易概括,当然所谓的research也不可能是一蹴而就 novelty、results什么的全都完爆previous work。只是很多paper的出发点都不一样,导致看起来paper间差异很大,其实在我看来现在GNN还是一个比较混沌的状态,等着哪位X kaiming大神来盘古开天。(或者说GCN这篇就算是开天了?)
Note:这篇文章完全是为我本人量身打造,是为了未来的我复习GNN的时候有个参考。因此我面向的读者是有了比较充足的CNN、Graph知识背景的。
开山老祖 GCN
这一段大部分是我的臆测。。可以直接看结论。
给一个irregular的grpah/point cloud,我们可以从频域(specture)和空间(spatial)角度去解决这个问题
- 频域角度就是图信号映射到频域后再做卷积操作。(直接copy from zhihu,原谅我这一块其实并不是很清楚,因为现在的大部分work都不会提specture这个东西了。。。而且本身这个对数学功底要求就有点高,也许我真的phd了可以花时间研究这个?单就目前纯水paper的角度,这个建议不要碰,1.上手难,2.现在大部分SOTA都是spatial)
- 空间角度大概就是直接从点/线的关系入手,用这些关系来表示某种message passing。messgae passing的意思很简单,就是说给一个点,它会把它自己的信息(feature)传输给它的邻点,同样,它的邻点也会把邻点的信息传给它。大概有点像社会学里面的信息传输,譬如李巍长得很帅,一传十十传百所有人都知道我长得很帅这样。。(我长得很帅这个信息就被所有人收到了,这样在他们那的信息就是:我有个朋友/朋友的朋友长的很帅)
这篇GCN做的就是,从频域角度出发给了GCN的公式:
![[公式]](https://www.zhihu.com/equation?tex=H%5E%7B(l+1)%7D+=+%5Csigma+(%5Cwidetilde+D+%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D+%5Cwidetilde+A+%5Cwidetilde+D%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D+H%5E%7B(l)%7DW%5E%7B(l)%7D+)+%5C%5C+%5C%5C)
$H^l$就是第l层的所有点的feature,$\bar{A}$是加上identity matrix的矩阵,D是degree matrix为了normalization(结果其实比较接近mean),W就是映射到另一个空间增加信息量。
然后发现这个公式其实可以从空间的角度很elegant的解释,GCN的每一层其实就是aggragation + combing(encoding)
- $\bar{A}H$ 其实就是对于任何一个点,将自己的feature,以及邻点的feature 累加起来,加个D就是为了normalization($D^{-1}$ 其实就是mean),因为每次都累加层数多了这个值不爆炸了?而且有些点邻居本来就多怎么办?。
- $W^{l}$ 就是做一次combing啦,可以理解成投射到另一个空间增加复杂度(其实就是1*1conv,or FC,or MLP,哦,有的可能还会加个bias)
方法层面
GraphSAGE
这篇就直接不管specture了,直接从空间角度把GCN重新提了一遍,同时formally定义了aggregator这个概念,其实就是对于每个点,怎么将它自己及它邻点的信息聚合(aggregate)起来。然后还提出了几个方法。
- 不加自己的feature mean 。
- 加上自己的feature mean。。。
- LSTM。。。也许那个年代LSTM比较火吧。
- channel-wise的max sampling
注:aggregator其实总之不管是什么,都只要保证order-invarienty以及size-insensitivity就行了
GAT
这篇就是说attention效果这么好,我们也套用到GCN吧!(对不起这是我的小人之心🐶),实际上应该是:每个邻居可能重要性不一样,所以要加个attention!
![[公式]](https://www.zhihu.com/equation?tex=a_%7Blearn%7D(i,j)=%5Cfrac%7Bexp(LeakyReLU(w%5BWx_i,Wx_j%5D))%7D%7B%5CSigma_%7Bk%5Cin+neigh(i)%7Dexp(LeakyReLU(w%5BWx_i,Wx_k%5D))%7D%5C%5C)
a(i,j)就是点i对点j的重要性。但这个真把我秀到了,具体可以参见https://wadmes.github.io/2019/12/30/attention/
JKNet
这篇就是说DenseNet效果这么好,我们也套用到GCN吧!(其实background还是GCN层数过深,例如depth>2,就会出现oversmooth的情况,即所有离得近点的feature长的都挺像的。而离得远的点互相的connection又太小了,所以加个densenet就可以让他们connection不小了呀呀呀呀呀呀)
提到oversmoothing了就说下,其实直接原因是目前GCN的aggregation必须保证order invarienty,导致不像CNN里面的convolution kernel一样卷积时候可以带weight,想象一下CNN里面a pixel的右边是b pixel,传信息的时候用的是3*3kernel里面的(2,3)value,而b要传给a,就是(2,1)了,两个值不一样,所以不管传多少次都不会最后比较接近,除非(2,3) = (1,3),这就是GCN现在的情况,因为GCN不可能还有方向这个概念,或者说,给一个点a,他有邻居b,c,目前还不可能能分出b,c。。
DeepGCN
这篇就是说ResNet效果这么好,我们也套用到GCN吧!
然后除了简单的加个residual connection,还提出了一个GCN上的dialated convolution,个人觉得是比residual 更重要/有效的一点。大概就是:regular CNN里面dialated convolution可以很轻松的跳一个选一个这样卷积,但是GCN不好操作因为每个点邻居个数都不一样,而且还是无序的。这里的做法就是对于每个当前点,给其他点按照feature的欧几里得距离来个排序,然后就可以跳一个选一个啦!(其实有点做point cloud里面dynamic graph CNN那味了)
Dropedge
这篇就是说Dropout效果这么好,我们也套用到GCN吧!
不过这里的dropout其实不同于CNN里面对feature的dropout(其实对feature的dropout在original GCN就用了),而是对weight的dropout,即每一层有概率的remove edge,(脑补一下,其实就相当于把GCN的weight全为1 改成了有些为0有些为1啊!)
Position-aware Graph Neural Networks
这个不是借用CNN的一些technique的理念,说下大概思路吧。
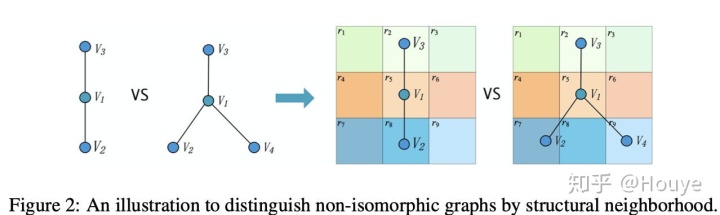
问题:GCN只能捕捉局部的structure 信息,比如:
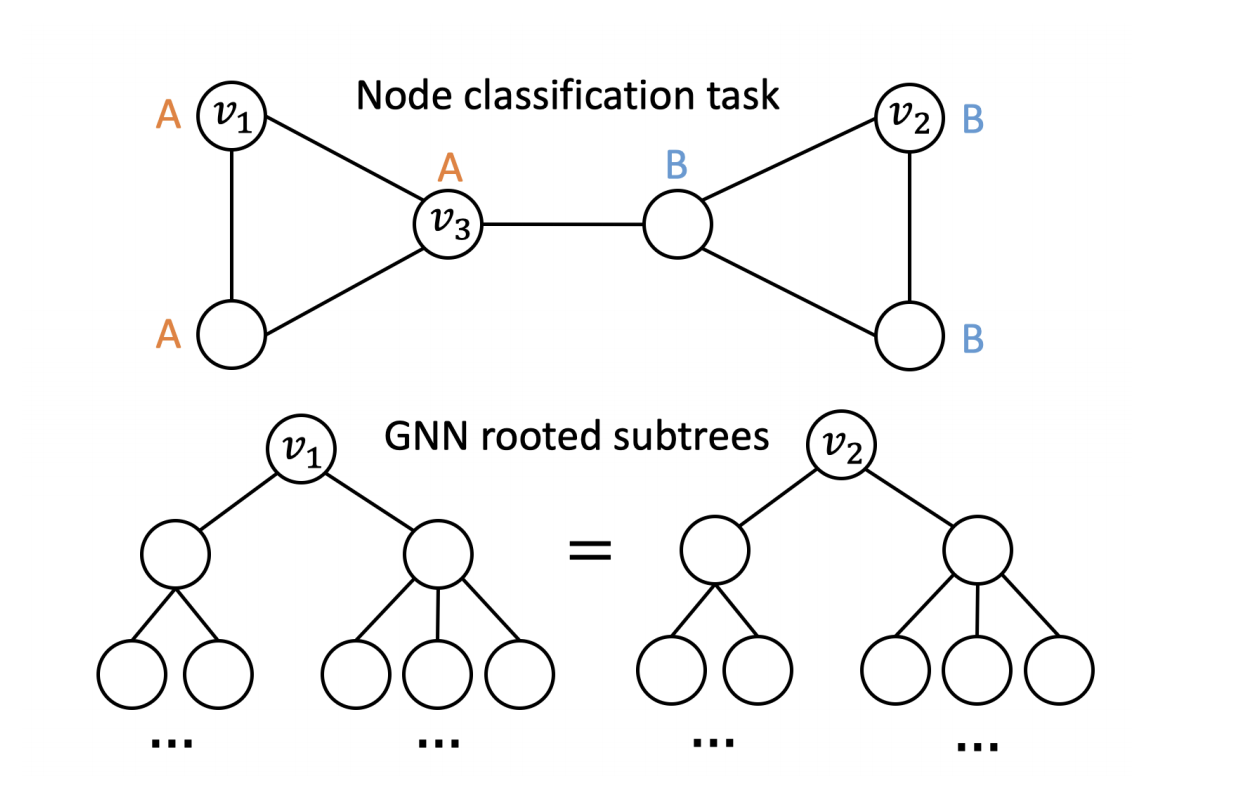
不管怎样$v_1,v_2$(structurally isomorphic nodes)都是分配同样的label。那么怎么解决这个问题呢?
node position can be captured by a low-distortion embedding by quantifying the distance between a given node and a set of anchor nodes
先说下workflow吧,
- 给$clog^2n$个子集$S_{i,j},i=1…\log n,j=1,…,c\log n$,每个子集会随机选择所有点,每个点被选中的概率为$1/2^i$,所以其实子集的大小其实是指数型增长的
- PGNN的每一层operation如下,
- 对于每个点,和每个子集里面的所有点(假设n个点)的featrue(假设d维) concat 起来->$n\times 2d$,如果子集里的点是距离为$k$外的(太远了),则return zero值(而不是concat feature)。接着把concat结果aggreate起来-> $2d$ (注意这里的aggregate也需要满足order invarianty!所以也只能用mean,max,sum等,作者直接用的mean)
- 对于不同的子集的结果再用aggregate $c\log^2n \times 2d \rightarrow 2d$。
总结:这篇的theorem用了Bourgain Theorem去证明只要$c\log ^2 n$个就子集就可以preserve the distances in the original graph with low distortion。。。不过很多paper里面的theorem都是比较巧妙的,让人觉着遥不可及。但是这个work解决GCN只有local structrue的大概方法也是类似的:就是想方设法的介绍一些global information进去,这里是通过介绍子集的方法,相当于给子集中的每个点多了一个额外信息:属于哪个子集。打个比方,假设所有人只有性别这一个label,我和坤坤都只有三个男性朋友,一个女性朋友,这样一层GCN就无法通过信息传输判断我的label了,但是如果创造2个子集(身份),分别是 爱rap的同学 和 爱打篮球的同学,然后发现我有一个爱rap的同学,2个爱打篮球的同学,坤坤有3个爱rap的同学,这样我和坤坤的label就是不一样的了。
COLORING GRAPH NEURAL NETWORKS FOR NODE DISAMBIGUATION
引入了universal representations & separability的概念,claim MPNN不是一个universal representation。解决方法(甚至出发点)和上篇paper有点相似。大概就是给node attribute 相同的点 从k种颜色中随机选一个颜色标上,k为hyper parameter,这样就实现了universal approximation。有两个concern
- 若k不为 graph size (即所有点颜色都不一样),那么这种coloring sheme不是permutation invariance。这也是ICLR被拒的原因。
- k=1时,不就是所有点assign一个相同的颜色么。。没看懂。。。
GeomGCN
同样,这个也不是借用CNN,说下大概思路吧。
Generalization and Representational Limits of Graph Neural Networks
定义decide:一个GNN Q如果decide了一个图性质P,则说明图性质P不同的两个图,由Q产生出来的graph embedding也肯定不同。
这篇文章前半部分就是用一些例子证明了:
- (用一些反例)基于聚合的很多GNN不能decide很多很简单的性质。
Simple and Deep Graph Convolutional Networks
Use two simple techniques to make GNN deep
Partially aggregate the input feature $H^0$, instead only aggregating previous layers features from its neighborhood
Adding a partial skip connection part
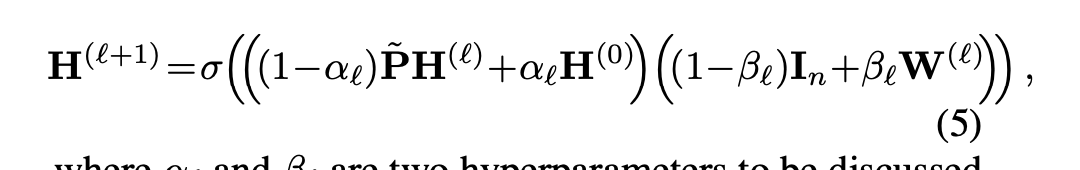
PAIRNORM: TACKLING OVERSMOOTHING IN GNNS
Another paper to handle with oversoothing issue in GNNs, i.e., cannot generalize to deep network.
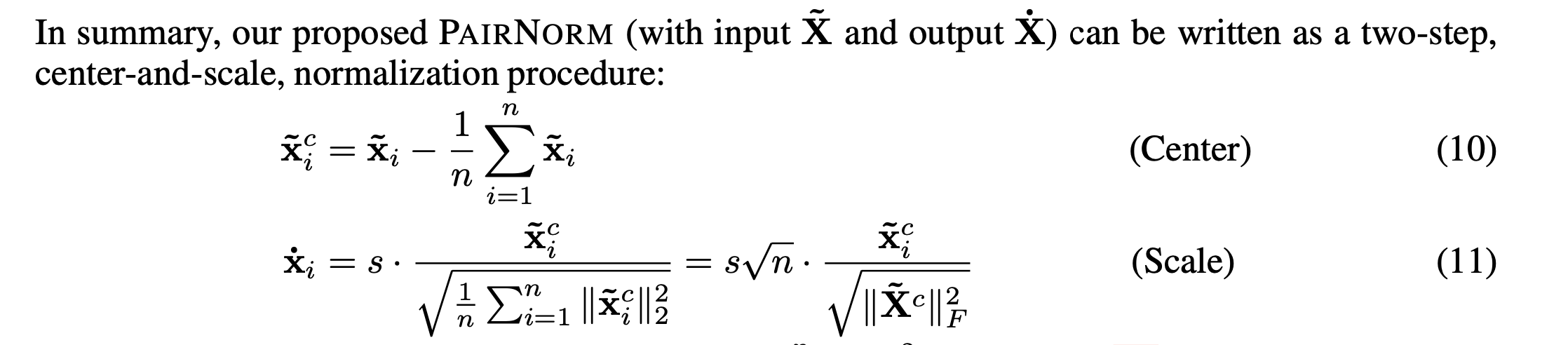
Here, n is the number of nodes.
The normalization is simply used for the output of each layer
Simplifying Graph Convolutional Networks
Non-linear 在很多任务中没什么用,GNN可以直接用一个很简单的linear model来表示:
$Y = softmax(S^KXW)$, where $S = normalized \ A$
理论层面
GIN
这个算是个人觉得最有意思的一篇了,大概就是说在座各位基于这种聚合的都是垃圾,最多也只能和从前的WL Test一样。https://wadmes.github.io/2019/09/14/GNN-GIN-GMN-study/
Weisfeiler and Leman Go Neural: Higher-order Graph Neural Networks
A very good paper that proves a similar conclusion with GIN. (the difference is that they use linear transformation instead of MLP, and finally claim that double the layers (which becomes MLP actually) can have the same performance with WL test)
And then propose a k-GNN based on k-dimensional WL test. Basically, the “supernodes” is all k tuples of the graph.
THE LOGICAL EXPRESSIVENESS OF GRAPH NEURAL NETWORKS
这篇(ICLR2020)大概就是接着上一篇GIN(ICLR2019)说,诶,确实以前的聚合(自己的+邻居的)都是垃圾,但我这个不一样了,对于每个点还有了个全局(readout)信息。
首先先从一个最简单的给点二分类的问题说起:如果要判断一个点是不是isolated node。我们是不是就没法正确分类了?因为true的点肯定没法传输信息。这个例子实在是妙啊。。
那么这个全局信息是什么呢?就是所有node feature的sum啦。。(ps。。头皮发麻)
WHAT GRAPH NEURAL NETWORKS CANNOT LEARN: DEPTH VS WIDTH
这篇文章的作者。。emm。。怎么说呢,一看就不是国人同时又是为计算机基础知识特别好的大神。
文章的证明需要比较强的计算机背景,不过结论很简洁易懂:
该研究证明,如果我们想让 GNN 为常见的图问题(如环检测、直径估计、顶点覆盖等)提供解决方案,则节点嵌入的维度(即网络宽度 w)与层数(即网络深度 d)的乘积应与图大小 n 成正比,即 dw = O(n)。
Approximation Ratios of Graph Neural Networks for Combinatorial Problems
这篇将GNN和distributed local algorithms 结合了起来,先证明了GNN和distributed local algorithms 是等价的,然后利用以前work对distributed local algorithms的研究得出的结论直接给出了GNN的一些结论。
大概就是现在两种GNN, MB-GNN 和 SB-GNN都比不上 VVC-GNN,定义分别是:



因此,提出了一个VVC-GNN。大概意思就是给别一个边的两个出口都assign一个port,使得所有点给它邻点的信息完全不一样。
最后实验就是用这个model + reinforcement learning 证明了 这个model可以解决很简单的组合优化问题,但是MB,SB都不可以。
在我看来,有个点是没解决的:
- 这种方法注定导致不能迁移到其他graph(相当于给每个edge的port一个人为的index)
- 这个方法训练时间需要很久,但同时不能用到其他graph。。也太扯了吧。
关于distributed local algorithms的定义,请参考 https://arxiv.org/pdf/1205.2051.pdf
Distance Encoding – Design Provably More Powerful Graph Neural Networks for Structural Representation Learning
添加了一个distance encoding to encode certain distance from S to a node u, 其中S是图中的一部分structure,想学的target structure feature就是S的feature,若S为全图,则为全图的feature(graph embedding).
这里的distance encoding 有比较复杂的formal形式,但是实验里面用的其实就是最简单的两点之间最短距离。
Design Space for Graph Neural Networks
Motivation:
- Surging new GNN tasks, with different requirements
- Large design space of GNNs
Design space:
- BN; Number of Pre-process layer (MLP); Number of Message Passing Layers; Sum/Mean/ and son on
Task space:
- Synthetic tasks: node features/ labels/ node/graph classification
- Real-world tasks: 6 node classification benchmarks from [26, 28], and 6 graph classification tasks from [14].
GraphGym
- Modularized GNN implementation
- Standardized GNN evaluation.
- Reproducible and scalable experiment management
Results:
- BN good!
- No Dropout good!
- PRELU good!
- SUM good!
- Adam good (compared to sgd)
- 400 epoch good than 100,200
However, besides these “common-sense” conclusions, desirable design choices for Aggregation, Message passing layers, layer connectivity and post-processing layers drastically vary across tasks
Tasks can be roughly clustered into two groups:
- (1) node classification over real-world graphs; with rich node features; GNN designs that can better propagate feature information are preferred;
- (2) node classification over synthetic graphs and all graph classification tasks; require graph structural information
How to determine the “best” design for a new task?
- using $M=12$ echor models to test the task,
- find the most similar task based on the rankings of the echor models.
- use the best design of the most similar task as the “best” design
Identity-aware Graph Neural Networks
Background
- MP GNN cannot distinguish nodes with the same computational graph.
- Although task-specific feature augmentation; is not generic and hamper the inductive power
- Previous works task specific; and not based on MP GNN->not efficient
DropGNN: Random Dropouts Increase the Expressiveness of Graph Neural Networks
非常漂亮的文章!
大概就是GNN的upper bound是WL,那么有没有可能突破这个upper bound呢?方法是简单的randomly drop node,这样一个graph 就对应成了 一堆graph 的distribution,那么不同graph 的distribution大概率是不一样的!
这个问题是相同graph的distribution也可能不一样,除非randomly drop的次数足够多,就像投硬币一样。文章里面还给了solid proof about the probability of the distribution close to the real likelihood.
将statistics 里面的一些东西运用到graph里面来,感觉很有潜力啊!
Some other interesting papers
NEURAL SUBGRAPH MATCHING
Done by Stanford Group. The problem is to determine the presence of a given query graph in a large target graph.The key insight that makes NeuroMatch work is to define an embedding space where subgraph relations are preserved. That is, : If $G_v$ (k-hop neighborhood of node v) is a subgraph of $G_u$, then node v should be embedded to the lower-left of u. Such relationship is preserved in the embedding space by an elegantly-designed loss function:

Beyond Homophily in Graph Neural Networks: Current Limitations and Effective Designs
This paper discusses GNNs in graphs where connected nodes may have different class labels and dissimilar features.
Three techniques are used:
- concatenate aggreated features insteaed of sum or mean them
- Higher-order Neighborhoods, concatenate two-order neighborhood
- concatenate (at the final layer) all learned ego-representations at previous layers
后记
写完后,忽然发现了一个也可以算巧合的规律吧?所有方法层面的work基本都是国人lead,但是理论层面的work却寥寥无几。这算不算是一种悲哀呢?方法层面的东西固然重要、效果好,容易发paper,但是理论层面的才是有可能真正推动时代进步的那个钥匙,不过似乎大家都对这种“不好发paper”、“没有确定性”、“难入门”的东西有一种共识性的排斥,算是一种悲哀吧!
其实自己何尝不是这样呢。做了五六个work,除了openmpl,其他的基本都是比较讨巧,迎着市场需求(学术圈热点)做的东西。这是这个时代的无奈,也是我个人的无奈吧,其实也是蛮想做一个沉下心学习研究一两年然后真正contribute to the development of CS的东西,可是现在还只是一个再过几个月要靠publication去砸PHD commitee脸的小小mphil;就算phd了也只是一个担心qualification、担心graduation的PHD student/candidate;就算当教授了也需要paper去争tenure啊;就算当了professor,也得对学生负责,在他没有成果前不可能让他做一些我自己都无法保证的东西吧?好像真正可以肆无忌惮做这种work的时间段只有achievement差不多时候的PHD year4/5了?
扯的有点多,说回GCN吧。总的看来,其实各种technique/theory还是在发展中的,不过里面确实还有很多可以发掘的东西,而且从功利化发paper的角度,不仅仅是Common GCN, 很多子分支,譬如point cloud,譬如heteogeneous graph(参考[https://wadmes.github.io/2019/12/17/heterogenous%20network/](https://wadmes.github.io/2019/12/17/heterogenous network/)) 这些子分支都是水paper的好方向哪。。
另外就是虽然所有paper的conclusion或者method看起来很简单:这不是本科生都能想到的吗?但是里面的story writing绝对是我得好好研究的:怎么将一个简单的solution包装的很elegant,它解决什么问题的?有什么理论去支撑的?实验怎么设置?这里面都是学问啦。总之,虽然novelty不够,但是发现了这些work的一些共同点:
- 大部分都有看起来牛逼哄哄的theorem/proof(对不起因为大部分theorem我没有仔细看,所以只能暂时说看起来。。。)
- results部分不会特别出彩,但肯定不是完全比不上别人。1% improvement 🐶,当然如果是专为解决特定问题的,譬如logical问题的那位,就是可以完爆了。