Untitled
从中国最贫困之一的县城到在世界计算机最顶尖的殿堂之一提交我的毕业论文,我需要感谢太多的人。
但我最应该感谢的是我的导师,Shawn Blanton和Jose Moura。
Prof Blanton对我来说不仅是mentor,更是朋友。他给了我许多一针见血的方向和技术上的指导,同时在他身上我也学到了许多科研之外的软实力,比如如何更好的present work。
我还需要感谢Prof Moura,他是如此的博学多识 and supportive。他对科研的认真、对学生的态度 也是我毕生所有追求的榜样
我也需要感谢我的thesis commitee:
Prof Subhasish Mitra 和 Prof Sam Pagliarini。Prof Subhasish Mitra让我学会了如何从更宏观的角度去思考问题本身、而不仅是方法层面。
Prof Sam Pagliarini也对thesis提出了许多宝贵的建议。
感谢我的labmate
- 感谢Dr. Ruben Purdy, Dr. Chris Nigh。他们在我整个phd期间帮助了我太多。多到这里的一两句话肯定不能概括他们对我的帮助。
- Yixin Liang, Christopher Ellis, Srinivasa Pranav, Shreyas Chaudhari, Oren Wright, Kawisorn Kamtue, Tong Shen, Jong-Ik Park, Prabhu Vellaisamy, Ziyad Alswaidan, Je-Wei Chuang, Xu He, Garrett Walker, John Shi。(特别的,感谢Pranav一直以来对lab的贡献)
(这是我带着做research的本科生)感谢我带的本科生Yang Zou,这段共同成长的旅程有你真好。
(这是我几次实习的mentor和advisor)感谢Ala Qumsieh,Dongjin Lee,Mark Ren,Rongjian Liang,你们让我见识到了技术如何落到实地。
(这是我们lab一直以来合作的企业的人员)Phil Nigh, Mark Adams, Bharath Parthasarathy, Ramesh Abhari
(这是给我发过fellowship和scholarship的)此外,还要感谢Apple,Qualcoom,Croucher Foundation对我的fellowship的支持和认可。
感谢我的妻子 Si Yu,。You are the real doctor. 和 我的儿子(一岁)Lucas Li。感谢我的父母 Yuebin Li 和 Shengmei Wei。
放弃了去startup之后
因为朋友的邀请,过去几周,我阴差阳错地和几位硅谷明星 startup 的 founder 聊了好几轮。当 offer 最终摆在我面前的时候,其实我是有点诧异的。对一个做 EDA research 的人来说,这个数字,是几年前的我完全不敢想象的。
说实话,在最开始的一两天,我确实很心动。尤其是在网上问了一圈意见之后——大概 80% 的人都觉得,这种「博一博财富自由」的机会不应该错过。有那么几个瞬间,我几乎已经决定接受 offer,甚至开始想象,该如何婉拒之后安排好的 Zoom 和 on-site interview。
但最终,我还是拒绝了。当然,这里面有很多现实层面的原因。比如我不太想因为签证问题,再被困在美国好几年;比如我觉得另一家 startup 可能更适合我。但如果说最深层的原因,其实是一个问题:
我究竟想成为什么样的人?
我究竟想成为什么样的人?
为了回答这个问题,我开始认真地和自己聊了几天。感谢 Gemini、GPT 和 Grok,它们帮我把这个有点抽象、甚至有点哲学的问题,拆成了一些具体的小问题。其中有一个问题是:
你什么时候会进入心流?
我发现,对我来说,心流往往出现在这些时刻:
读到一篇很有意思的 paper;
和别人讨论 idea、碰撞想法;
在课堂上讲知识,或者和学生聊他们的问题。
如果说有什么事情让我特别有成就感,那往往是:
我感觉自己正在正向地影响别人。
但与此同时,我也很清楚自己的“逆流”。
比如 debug 代码。
比如分析 fail log。
比如管理团队、分配任务。
这些事情我不是不能做,我在Apple,NVIDIA实习的时候做的也挺好,但这些事很难让我进入那种真正投入、忘记时间的状态。
这些观察也让我慢慢意识到一件事:也许我并不是一个特别适合在 startup 里搭基础设施的人。当然,我也会怀疑自己在research上的能力。毕竟做 research、发 paper,本身也是一件非常困难的事情。
我想过怎样的人生?
还有一个问题是:
如果生活没有任何压力,你最想做什么?
和Wuxi聊天的时候,我也忽然意识到自己经常会有的一种念头:
如果可以的话,我很想回到大学,再去上几门课。比如数学。比如 data structure。很多时候,这种念头都来自于读某篇 paper 的时候,突然意识到的书到用时方恨少。
此外,我一直有个和自己职业道路可能完全无关、但一直想做的一件事:做一个类似《三国志》的游戏。一方面,我很想做出真正的 AI。不是那种基于 heuristic 的决策树,而是能真正学习、博弈、成长的 AI。另一方面,我其实一直很喜欢历史。我也很希望,有一天可以把这些王侯将相的故事,以及他们在历史中的选择与挣扎,讲给更多年轻人听。因为当你看过很多这样的故事之后,你会慢慢意识到一件事:
那些曾经叱咤风云的人物,
最后也不过是史书中的一页纸。
当你意识到这一点的时候,其实会对自己的人生,多很多和解。
高三那年,一直都是全校第一的我,因为户口问题,失去了保送清华的机会。那可能是我人生中最大的一次打击。当时年少的我,其实是从苏轼的故事里慢慢走出来的。我读到当年庙堂之上春风得意的苏轼。也读到乌台诗案后颠沛流离的苏东坡。还读到那个纵使困顿、仍然乐享江上之清风、竹杖芒鞋轻胜马着的苏子。
从那以后,这件事情对我来说,慢慢变成了一种信仰。我可能会在不同的选择面前犹豫。也可能会因为 paper rejection、失败的面试而懊恼一阵子。但总体来说,我一直都是个比较乐观的人。就像最近刷到大冰的一句话:无所吊谓,都得死。所以对我来说,一时的失意,甚至长久的挫折,其实就像天地间的蜉蝣,都不算什么大事。成为 millionaire 或 billionaire,对我来说也没有太大的吸引力。我真正比较在意的,是另一件事情:当很多年以后回头看自己的人生的时候,我能不能对自己说一句:问心无愧。
什么才是自己的方式?
“问心无愧”其实和我很多年前读明朝那些事时的那句话是一个意思:
成功只有一种:按照自己的方式,度过人生。
但以前我一直忽略了一个问题:
什么才是“自己的方式”?
或者说,许多人这一生,即便嘴上说着要follow your heart,但其实根本不知道什么才是heart所指的方向。
在我的三观还很混沌的时候,我就很喜欢武侠故事。“侠之大者,为国为民。”那时候的我,其实很认真地把这句话当成一种人生目标。刘备携民渡江、诸葛亮为报知遇之恩鞠躬尽瘁。这些故事,在我看来都浪漫得不得了。所以我一直希望,自己有一天也可以成为一个“侠”。
后来我发现,其实科研世界和武侠世界有很多相似之处。有江湖、有师父、也有人情世故。每个实验室就像一个门派,每个组都有自己擅长的领域。那些最厉害的教授,就像一代宗师。而我们这些年轻人,不过是刚刚“初出茅庐”的小辈。
如果从这个角度来看。对我来说,做 faculty 其实是一件很浪漫的事情。每一次上课,其实都是一次当“大侠”的机会。我在传播知识、我在影响年轻人、我在帮助他们找到自己的人生方向。与此同时,我也在努力推动一点点生产力的进步。如果能做到这些,那对我来说,大概已经是很不错的人生了。
当然,这几天,当我真的认真思考这些问题的时候,我也发现自己其实有很多拧巴的地方。
比如,我一直告诉自己要做一个“大侠”。我希望自己能像那些历史故事里的英雄人物一样,有自己的原则——信、义,像“报君黄金台上意”那样的担当;我希望自己能保护身边的人;也希望自己能够尽可能多地,给别人、给这个社会带来一些正面的影响。如果有一天能够“达则兼济天下”,当然很好;但即使做不到,也希望自己至少还能“穷则独善其身”。
但与此同时,我也常常会怀疑自己。我其实很怕自己会变。我会想:现在的这些“侠义”,是不是只是因为我还人微言轻?如果有一天真的有了权力和资源,我会不会和我爱读的那些武侠故事里面的经典桥段一样。。。
如果有一天我变了呢?也许那时候,我对自己会很失望。甚至可能会有一种人生观崩塌的感觉——像我曾经读到的白孝文的故事那样。所以我也会反过来问自己:是不是我给自己设定了太多责任?人生是不是应该卸掉一些“必须如此”的执念,才能活得不这么拧巴?
Gemini给我的一段话,让我很受触动。
最开始闯荡江湖的少侠,追求的往往是无拘无束、快意恩仇。
但真正到了境界大成的宗师——比如守襄阳的郭靖——哪一个不是满身疲惫,被家国天下的责任牢牢拴住?他们是被束缚了吗?其实不是。是他们自己选择,把这些重量扛在肩上。当一个剑客有了真正想保护的人,他出剑的时候,才会真正有力量。 所以,也许所谓的“责任”,并不是枷锁。它只是我们在成长的路上,慢慢愿意背负起来的东西。
这篇文章没有真正的结尾。就像我的人生,也还远远没有到终章。
但至少现在,我还只是那个踏入江湖的少年。带着一点理想,也带着一点拧巴,还在继续走下去。
多任务优化的那些事 - Study on Multi-task Optimization
知道DEFT被DAC拒了后,化悲愤为动力,作此文
P.S. 什么样的结局。才配得上这一路颠沛流离。。。以后起标题建议用FAKER,MJ 之类的名字。
自从大模型之后,这样的技术博客逐渐丧失了它的原本意义。Gemini总结的比我好多了,你甚至可以让它给你写一份给洗脚城大爷科普的文章。之所以还要在这记下我的一些拙见,主要还是一个inspire的作用 - 也许有人读了这文章后发现这玩意有点意思,有点启发呢。至少对我来说,这对differentiable programming很重要。(at least Gemini is a passive chatbot now)
当我们需要优化多个任务,而这些任务很多时候conflict的时候,理论上我们直接取gradient平均值就好了。但是当landscape曲率过大的时候,这种step更新的backpropagation就会导致一个问题 - 高估了我沿着dominating task走的benefit,低估了给dominated task带来的伤害。(cite: Gradient Surgery for Multi-Task Learning)
那么我们有请解决这个问题的选手们入场
- PCGrad (Gradient Surgery for Multi-Task Learning)
这位选手指出 把所有task的gradient 都project到和他conflict的task的gradient的normal plane上,这样就没有conflict了!大概如下: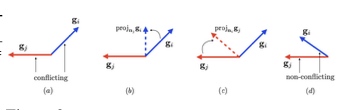
- FAMO: Fast Adaptive Multitask Optimization
这位选手指出,我们使所有任务在对数空间下的下降速率对齐。(这个背景是表达有一些任务被under-optimized了)
它维护一个辅助变量 $z_i$(可以看作是权重的 logit 值),根据 Loss 的变化进行更新:
$$z_i^{(t)} = z_i^{(t-1)} + \gamma \left( \log L_i(\theta_t) - \log L_i(\theta_{t-1}) \right)$$
直观理解: > * 如果任务 $i$ 的 Loss 在这一步上升了(或者下降得比别人慢),$\log L_i$ 的变化量就是正的或者较大的。这会导致 $z_i$ 增大,从而在下一步中增加该任务的权重。
- Nash-MTL:
将多任务优化看作一个纳什议价问题(Nash Bargaining Problem)。它的出发点非常硬核:不再强行投影梯度,而是让各个任务通过“谈判”达成一个大家都满意的更新方向。核心逻辑想象 $K$ 个任务在分一块名为“参数更新”的蛋糕。每个任务都希望梯度更新方向 $\Delta \theta$ 尽可能靠近自己的梯度 $g_i$。Nash-MTL 寻找一个方向,使得所有任务获得的改善(Utility)的乘积最大化。其目标函数定义为:
$$\max_{\Delta \theta} \prod_{i=1}^K \langle g_i, \Delta \theta \rangle \quad \text{s.t.} \quad |\Delta \theta| \le \epsilon$$
转换为对数形式后,这等价于:$$\max \sum_{i=1}^K \log(\langle g_i, \Delta \theta \rangle)$$
为什么它比 PCGrad 高级?尺度不变性 (Scale Invariance): 这是 Nash-MTL 最杀手锏的特性。即便任务 A 的梯度量级是任务 B 的 1000 倍,在对数空间下,这种量级差异被消解了。这完美解决了你之前提到的“大梯度主导平均梯度”的问题。帕累托最优保证: 数学上可以证明,纳什议价解必然落在帕累托前沿(Pareto Front)上,这意味着在这个方向下,不损害其他任务就无法进一步提升某个任务。解法: 在实际实现中,它通过求解对偶问题,将 $\Delta \theta$ 写成各任务梯度的加权和 $g = \sum \alpha_i g_i$,并动态迭代计算权重 $\alpha_i$。
我发现Gemini比我总结的好多了。。。
Hint - 可以发现这些work 他们想要解决的multi-task的issue都是不一样的(虽然都是解决Multi-task问题)。对应到我们concern的问题上,可以发现ML community关注的点是所有任务都要雨露均沾(fairness),他们的底层假设都是 “共赢” (Collaboration),但你的任务真的是这样的么?
2025年九月的随笔
Neway,好久不见。
在现在落笔之前,我一直在酝酿给Lucas写的信,我想告诉他现在的世界是怎样的,想告诉他爸爸妈妈有多爱他。但忽然某一刻,我认知到,也许给他的信,不用刻意写出来,他成长的每个瞬间的我的陪伴,就是最好的注脚。
但是我必须要和你聊会了。每次当我回过头读那些写给我们的信时,我都能立马捕捉到我在那个当下的情绪甚至画面。因此,在这个发生了太多事的2025年,在这个也许是人生最大节点的时候,我必须写点什么了。
我不知道读这封信的你会在哪里、从事怎样的工作,但我知道你能立刻感受到我现在的迷茫。
从我决定读博的时候,我就坚定的想找教职。最大的原因是因为我喜欢在台上教书、和学生们进行有趣精彩的思维碰撞——我到现在仍是如此,上周Blanton开会去了让我代一节课,对我来说,那也是一次无比有趣、放松的体验。
但是我并不是很卷的人。也许是在媳妇的陪伴下、在Jose的鼓励支持下、我庸庸碌碌但却乐呵乐呵的过了博士这五年,我不觉得牺牲自己的时间精力换取事业上的成功是很明智的一件事:人生有太多值得体验的事物。换句话说,我并不是那么的self-motivated。我不像马哥,zhuolun,Zhengqi,和他们聊的时候,我能明显感觉到他们有野心:这不一定是作为AP成功的充分条件、但一定是必要条件。
正因如此,让我犹豫找教职的另一个原因是,我害怕辜负了我的学生。我作为PI,没有足够的self-motivation,怎么可能可以motivate我的学生 让他们的PhD生涯成果满满、或者至少不用担心毕业前景呢?
另一方面,我觉得自己的high-level的vision很有限,当我只是independent researcher时,我只需要自己捣鼓自己感兴趣的东西。但如果我有需要对他们负责学生,我肯定不能就像现在这样想做啥做啥。因此,倘若我做了AP招了学生,这些忧虑会push我不得不多去和工业界、和前辈交流,不得不每天多看N篇论文,花比现在多得多的时间在research上。那这似乎又和我一直以来的看法冲突了:
我不觉得牺牲自己的时间精力换取事业上的成功是很明智的一件事。
我当然对research有兴趣。事实上,和上课类似,每次paper的讨论都让我很兴奋。那如果这么看,去公司做research scientist,也许才是最适合我的路?不需要对别人负责(或者说,我只需要对manager负责,完成TA对我的expectation)的同时还可以和一群聪明人探索尝试很fancy的东西。
但是你要让我下定决心走工业界,我也会开始犹豫、难断——我甚至会脑补一堆逻辑去推翻我之前的想法:比如学术界获得vision不一定就要导致花比现在多得多的时间在research上:你不需要deal with those messy coding and implementations。比如我的内心并不是害怕对人负责、而是害怕自己的能力不够导致辜负对ta的负责。
哎。
其实当我从旁观者的角度,我可以给自己一些宽慰的建议——譬如不管怎么选,最后结果肯定还不错,所以不用太纠结。但是真的让我自己选择时,我确实没法下定决心:
留美国?美国的政治环境、和父母相隔万里。
回中国?从17岁后就没在大陆长期生活过、大陆的生活、工作环境我习惯吗?一直听说很toxic,如果不习惯怎么办?这大概率是一条单向路。
去工业界?真的要改变自己长久以来的想法吗?
去学术界?之前已经说了。。
其实还有很多想说的,比如对LLM的看法。但是Neway 我要去开会了,那就贴一下之前朋友圈的碎碎念吧。
我第一次lead的project是写一个要开源的版图分解工具。在抓耳挠腮的理解算法、码代码、debug的某个晚上,忽然发现老板十年前的某个formulation有缺陷,导致在某个case结果并不是最优解。
基于此,我顺利publish了第一篇一作ccfa。
之后AI火了,但对我来说 什么cnn gnn只是多了一个工具,可以让我更加得心应手的解决问题。
在这个过程中,我也偶尔会灵光一闪的想出一些自己很喜欢的idea,比如基于SDP的floorplan。
但自从LLM之后,尤其是在做LLM相关work的时候,我发现自己对科研的乐趣正在慢慢消失。我越发觉得自己不再是那个探索者、那个战士,我只是LLM雇佣的一个民工,负责抬着LLM横扫寰宇,甚至LLM也许根本都不需要我抬。
我曾经绞尽脑汁才发现的老板的bug,曾经的那些灵光一闪,对于LLM来说也许只需要合适的prompt或者Agent flow,然后就是几秒钟inference的事情。
我不知道怎么结尾,也不知道怎么和这个事实和解。人生的酸甜苦辣,真是有意思呐。
Circuit Fusion Read Note
Circuit Fusion
Basic idea: learn a fusion circuit embedding by fusing different modalities: RTL code, function description, netlist graph, RTL AST.
Data
41 RTL designs - 7,166 RTL sub-circuits - generating same function 57,328 sub-circuits (Each with 8 sub-circuits)
summary - coming from GPT4 (prompt input is the verilog code)
code - existing
graph - obtained by code. nodes are operators.
How circuit is divided into sub-circuits?
Training details
Intra-modal learning
- mask circuit graph nodes (operators, e.g., AND, XOR, MUX) and predict the masked nodes
- intra-modal contrastive learning: positive sample - sub-circuits with the same functionality
- Q: How to create same functionality and ensure it is correct? A: using open-source tools, Yosys and ABC
Cross-modal alignment
Multi-modal fusion
- Mask summary modeling
Query: Masked summary embedding (randomly masking parts of high-level summary)
Key, Value: Mix-up of code-graph
Q: why not simply mix-up everything and feed into a transformer (self-attention)
- Summary and mix-embedding matching
Alignment w. Netlist - RTL
What is RAG inference here?
Evaluation: what tasks?
- predicting slack for each individual register (sub-circuit level)
1 | slack calcuation example (thanks deepseek) |
- worst negative slack (WNS) prediction
- total negative slack (TNS) prediction
- power prediction
- area prediction
The four above is circuit level
Q: how to use sub-circuit emebeddings to do circuit level predictions? Concat? If concat, how to handle the number of sub-circuits that changes for each design? A: They add them up. And then concat with some design-level features (what is included in their exp), and then use a regression model.
Q: This compares with SNS v2, but it seems to not publish the code?
Note: in circuit-level tasks, they include design level features, e.g., number of different operator types. We need to figure out what features they use.
Autograder简单的中文教程
前段时间想给一个作业写一个autograder,翻遍网上发现没有中文教程,遂作此文。(也是给自己留个备份 方便之后直接看)
首先准备一个文件夹 autograder_folder。注意这个文件夹里的内容会被上传到服务器中的/autograder/source
第一步
创建setup.sh,这个是autograder server第一个执行的脚本,一般来说,你可以用来给autograder server装环境。例子:
1 | #!/usr/bin/env bash |
第二步
创建一个脚本run_autograder, 其中的内容大概就是
- 复制学生的submission(在
/autograder/submission里面)到某个你需要的地方 - 跑学生的submission
- grading
例子
1 | #!/usr/bin/env bash |
Grading?
grade需要两个文件,run_tests.py
1 | import unittest |
和 tests/test.py
下面是我的例子,主要看下每个func 的前缀,很好理解。
1 | import unittest |
最后
注意不要压缩autograder_folder 这个文件夹,
要选中autograder_folder里面的所有文件然后压缩
2024年六月的随笔
武侠和科研
最近通关了一款武侠游戏,逸剑风云决。我在steam上的评论有了快一百点赞:
我也算是个科研工作者,在我看来科研世界和武侠世界有很多相似之处。
有江湖 有师傅 有人情世故,每个组(门派)有自己擅长的领域。
做的最好的教授就像那些一代宗师们,而我们就是“初出茅庐”“炉火纯青”的小年轻。
而宇文逸的故事真的有给到我激励:不论处在什么位置,保持善良、保持初心,努力学习,坚持正义,作出一些为国为民的贡献,便是自己的侠心,每个人都能做到的侠心。
其实我年少时并没怎么读过金庸:在我那个年纪读“武侠小说”不算是“正经事”的。不过我有幸读完了成语故事,并且对里面的各种历史故事颇有兴致,也许我是那时起便埋藏了对自己这个民族、文化的热爱。
我真正接触武侠是到了大学。从侠客风云传到射雕英雄传,最开始的喜欢其实更多是因为它游戏中能带给人的“爽感”:主角获得绝世神功完成复仇,迎娶意中人,这样的故事是我这样的青年喜闻乐见的。
不知何时起,我喜欢的武侠不再是那些武林绝学、江湖奇遇,反而是郭靖守襄阳的义不容辞、黄蓉陪伴郭靖的生死相随。在我看来,这些品质,是超脱于那些江湖、绝学之上的,更为难得、并且更值得我们学习的。
也许是“有人的地方就有江湖”,另一方面让我觉得有意思的是,在这种武侠游戏中,经常会有 把我逗笑、让我觉得和自己的生活好像 的情况。
主角参加武林大会,和各路没见过的掌门帮主问好,掌门帮主们第一句话就是问你是不是xx(武当掌门)的关门弟子。
😆
这不就是我去DAC开会和各路大佬们打招呼,他们都会问我是哪个学校、导师是谁一模一样?
然后各个门派的招式就是各个组擅长的领域。有的组擅长phyiscal design,有的组用ML比较多。。。类比起来就是 少林打拳的多,姑苏家很喜欢用斗转星移之类的“妖术”。
那这么说我的SDP方法算不算自己发明了一门武功(虽然搁游戏里肯定就是一个白色最垃圾武功),但好歹也是个原创对不。😆
因此,我每每学一些新东西时、譬如RL,diffusion model,我总是莫名其妙会涌出一股兴奋感:卧槽,我可是在读一门武林绝学呢!这秘籍不用从猴子那拿、不用给神仙姐姐磕头,直接就给我了!
遗憾和人生
人生最大的遗憾,是一个人无法同时拥有青春和对青春的感受。
最近实习去公司都是博一顺路接送我,所以每趟我们都在路上嗨聊。
自然聊到了一些人生中遗憾的事。
如果真要聊,我可以哔哩吧啦一大堆:
“我跟你说,我本来是个天生的画家,小学时xxx。。。”
“诶,我小时候还自己做游戏,无敌的”
。。。
但真要说最大的遗憾,我也许会投自己成熟的太晚一票。因为成熟的太晚、所以很多对人对事,不论是对朋友、还是感情上,都有太多让我后悔做过或是没做的事。
我可以把一部分原因怪罪于这个高考至上的教育体系,这个忽视人文关怀的体系让包括我在内的学生没能在青少年时代建立起良好的感情观、人生观,只能空叹“初闻不知曲中意,再闻已是曲中人”。
但是我没法把锅全甩给体系。
事实上,我很认同deft的那句话
其实人生在世,是不太需要别人的建议的,不经历过不会明白的
语文课本里面学过的东西其实足够我们安然幸福的度过人生:我们学过对待外物要“不以物喜,不以己悲”、对待结果要“尽吾志也而不能至者,可以无悔矣”,也见识过“山无陵,江水为竭”的轰轰烈烈的爱情。
但是不经历过是不会明白的。
只有经历过,才会想:如果当时我XXX就好了。这么说来人生似乎是注定有遗憾的,但也正是如此,所以我现在坚定的支持探索,去体验,去勇敢的做自己的选择。只有多去做、才能多经历、才能真正的学到怎么和这个世界、和他人、和自己相处。
stabel diffusion 和 reinforcement learning 的优缺点对比
今天开完会 和同学仔细讨论了下SD 和 RL,受益颇多,赶快记录一下
Stable Diffusion
优点
- 一般质量很高。(当然SD is only for generative task now)
- 可以生成很多样本
- 训练稳定
PS: 这几点可都是EDA engineer喜欢的呀
缺点
需要“label” $x_0$
生成的样本 还是 在模仿”label”们的distribution,能不能超过label呢?这是个问题。如果不能超过“生成label的算法”的话,那么我们为什么不直接用“生成label的算法”?
关于这个问题多说几句,目前我看到的回答是。
- 没有“生成label的算法”,但我们也可以(反向)产生一堆100% accurate的label。比如我们的任务是 format A -> format B。虽然没有A->B的完美算法,但是有B->A的完美算法。于是我们random generate B, and then get its corresponding A. which is our training data (A,B)
- 没有算法,但可以很方便收集到label,比如SD用来生成图像。
Reinforcement Learning
优点
- 可用于各种问题,生成,决策,控制。
- 不需要“label”
缺点
- 训练很不稳定
- 怎么定义”很好的”action,reward,这些是个大问题
stable-baselines3的一些小技巧
Use gym wrapper
需要重写 reset() and step()
1 | class TimeLimitWrapper(gym.Wrapper): |
当然,如果自己写enviorment 就不需要 写wrapper了
logger 中的各种值
entropy_loss
entropy_loss: 负数值,越小代表预测的越不“自信”
if probs is [0.1,0.9]
entropy = -0.1ln(0.1) - 0.9ln(0.9) =~ 0.325
entropy_loss = -0.325
if probs is [0.5,0.5]
entropy = -0.5ln(0.5)-0.5ln(0.5) =~ 0.69
explained_variance
explained_variance, 用于计算how well value function (or critic in actor-critic methods) match the actual returns
~= 1: 完美
0: 和全预测一个值一样
<0: 比简单预测mean还差
RL Tricks I found in internet
http://joschu.net/docs/nuts-and-bolts.pdf
Premature drop in policy entropy ⇒ no learning
- Alleviate by using entropy bonus or KL penalty (鼓励randomness)
I was confused as to what action I should take to improve my results after lots of experimentation whether feature engineering, reward shaping, more training steps, or algo hyper-parameter tuning. From lots of experiments, first and foremost look at your reward function and validate that the reward value for a given episode is representative for what you actually want to achieve - it took a lot of iterations to finally get this somewhat right. If you’ve checked and double checked your reward function, move to feature engineering. In my case, I was able to quickly test with feature answers (e.g. data that included information the policy was suppose to figure out) to realize that my reward function was not executing like it should. To that point, start small and simple and validate while making small changes. Don’t waste your time hyper-parameter tuning while you are still in development of your environment, observation space, action space, and reward function. While hyper-parameters make a huge difference, it won’t correct a bad reward function. In my experience, hyper-parameter tuning was able to identify the parameters to get to a higher reward quicker but that didn’t necessarily generalize to a better training experience. I used the hyper-parameter tuning as a starting point and then tweaked things manually from there.
Lastly, how much do you need to train - the million dollar question. This is going to significantly vary from problem to problem, I found success when the algo was able to process through any given episode 60+ times. This is the factor of exploration. Some problems/environments need less exploration and others need more. The larger the observation space and the larger the action space, the more steps that are needed. For myself, I came up with this function needed_steps = number_distinct_episodes * envs * episode_length mentioned in #2 based on how many times I wanted a given episode executed. Because my problem is data analytics focused, it was easy to determine how many distinct episodes I had, and then just needed to evaluate how many times I needed/wanted a given episode explored. In other problems, there is no clear amount of distinct episodes and the rule of thumb that I followed was run for 1M steps and see how it goes, and then if I’m sure of everything else run for 5M steps, and then for 10M steps - though there are constraints on time and compute resources. I would also work in parallel in which I would make some change run a training job and then in a different environment make a different change and run another training job - this allowed me to validate changes pretty quickly of which path I wanted to go down killing jobs that I decided against without having to wait for it to finish - tmux was helpful for this.
- Comments to your last point: make more use of callbacks. https://stable-baselines3.readthedocs.io/en/master/guide/callbacks.html There are a lot of configured callbacks you can use to capture the best model, stop training on no improvement, regularly checkpoint… Lots of stuff. Be explicit about using Eval environment.