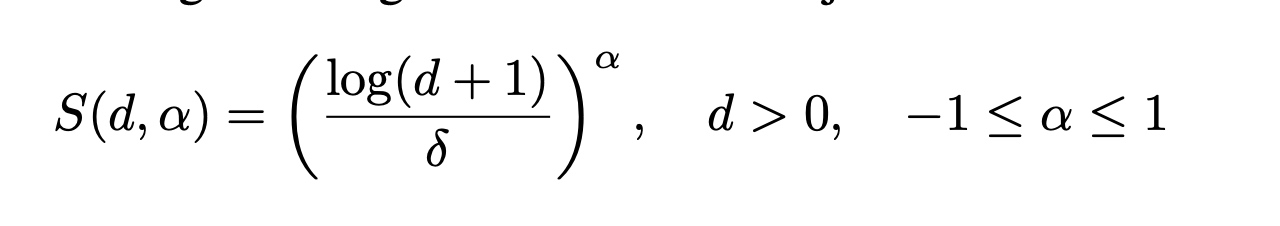引言
科学是一个继承与积累的过程,强如牛顿世不是一个人发展动力学、一个人收集整理数据!(Cohen 62) ,然而从牛顿运动定律到达尔文的自然选择学说,再到爱因斯坦的相对论原理 ,每次新理论的出现现往往伴随随对前人科学的否定。
本文将从探讨几位科学巨匠的继承与叛逆入手,分析继承与叛逆在科学的发展中所扮演的角色,从而思考其能给我们带来的启示。
科学巨匠们的继承与叛逆
牛顿
谈到科学史,牛顿是绕不开的话题。牛顿《自然哲学中的数学原理》《以下称《原理》)的问世是整个物理学史中最伟大的事件之一(Cohen 49),而牛顿也被公认为将科学与宗教分离的现代科学开创者(陈方正 595)。在后人看来,对于那个以亚里士多德体系为科学标准的时代,牛顿可以说是以叛逆者的形象出现的。而这点恐怕是牛顿万万没想到的,事实上,无论是在宗教层面曾用天体运动证明神的存在(Cohen 55)还是在数学层面对于古典几何学的发扬,牛顿都是一个古代传统的继承者而非叛逆者,这也与其本人想法一致(陈方正595)。
牛顿的自诩不无道理。现代科学革命是由古希腊科学的复兴所触发(陈方正628),牛顿的科学体系也有许多是继承了古希腊科学思维。牛顿在无数例子中提炼出了惯性定律,而古希腊科学也重视演绎和归纳,譬如试图将地、海、火、风这些常见的自然现象感景观归纳为构成世界的四种元素(Lindberg 27)。《原理》对定理的证明逻辑严密,对数学的运用也十分巧妙,这些也正符合古希腊科学的特征(Thomas 89)。
但仅将牛顿称为继承者又显不妥,牛顿的许多贡献,如微积分、实验科学是超出了前人的研究程度甚至理解能力的,而这些贡献又一定程度上颠覆了前人的科学体系或是思维方式,这也是牛顿会被大众视为“叛逆者”的原因。但我认为,牛顿的最好定义应当是继承者、发展者和叛逆者。一方面,牛顿继承了前人部分思维方式、吸收了同时代其他科学家们的实验或是理论结晶,最后发展出将数学、观测、思想三者系统的结合起来的崭新哲学(余英时),而这门哲学反过来颠覆了传统理论,即叛逆一说。
达尔文
作为另一个叛逆者的杰出代表,达尔文的叛逆显而易见,他认为自然选择使产生有利变异的个体有更好的机会生存并将这个有利变异遗传下去,而有利变异的逐步积累则产生了物种进化,后来便出现了人类这样的高等生物(Darwin 95),这对上帝造人说无疑是巨大的挑战。
事实上,达尔文不仅是个叛逆者。他分别吸收了莱尔地质缓慢变化理论,马尔萨斯的资源有限导致生存竞争的概念·拉马克的特征可传理论,并将三者结合起来,再联系自己的实验及理论最终形成了自然选择学说。
坎德尔
作为当代科学家的杰出代表,坎德尔的研究历程更值得深思。他不是以“叛逆者的形象出现,而是一位优秀的合作者,继承者。
在探索意识的生物学基础这个尚未有人“开发”的难题时,他的导师建议他从下而上研究神经细胞的内部世界进而探索更上层的心理结构理论(Kapde1180),而在探索负责意识统一性的分布位置时巨匠克里克给了他关于屏状核的启示(Kandel 190)。可见人类的知识已不可能由一个人来全方位的扩展,当代科学中多人合作已不可避免。
分析
如上,达尔文的历程与牛顿都经历了吸收他人理论、发展自己理论、推翻前人理论的过程。但两人本意并不是叛逆,他们只是在发展自己的理论后发现与传统理论矛盾,于是选择成为叛逆者推翻原有理论。
用一个比喻来说明继承、叛逆与发展在科学中的角色:将科学比作一张试卷,继承就像试卷前面的基础题,你只需学习前人的理论便可,而发展就像是后面没有标准答案的难题,你得推导出更深层次的理论才可能完成。叛逆的一部分是你推导理论时跳出前人知识圈子的能力,而当你做完后面的难题,得到了自己的理论,发现基础题根本不能按从前的方法做时,你冒着 0分的风险把基础题全改掉的勇气就是叛逆的另一部分。
至于当代高层次的科学,就好像是几个人一起做一张只有难题的试卷,大家各抒已见,互帮互助,互相吸收时方的思路,这是发展。而一张卷子用了好几代人的时间来做,后人看前人的思路来继续解题,这是传承。当后人发现的人的思路有问题一笔涂掉,这是叛逆。当然,最后卷子做完,这张卷子的题目以后就变成基础题等着后人来做了。
启示
对于我们学生来说,继承无疑是容易的,但发展则困难些,它需要我们去探索未知的可能,而叛逆则更显困难,因为我们首先需要一套严密的体系去推翻它,这需要有足够的知识,而学习时我们又得小心不要陷在原体系的思维局限中,这无疑更为困难。因此在学习时锻炼自己的思辨能力以及敢于犯错的能力是及其重要的。
但同时,我们也不能盲目叛逆·不顾前人已得到的经验而盲目的追求标新立异、妄图空想出一个改变整个科学历史的重大发现自然是不可取的。从牛顿到达尔文,没有一个不是在学习、实验无数小时、自成了一套严谨科学的体系之后才开始叛逆,尚不能行,焉能跑否?这在当代的科学环境中尤为重要。
相对叛逆,我们更应思考如何在继承的基础上发展知识。细说,我们在将目前的课程掌握的基础上可以把握大学广淘的资源,去深入探索更高层次的问题,广说,谁也不能断言爱因斯坦构建的物理大厚不会崩塌,但我们能确信的是科学将会一直发展,我们能做的就是学到人类知识边缘,然后以团队之力为科学开疆扩土,并将这份志愿传承下去。
总结
克里克说,如果他可以活得久一些,他就要做一个实验确认当某个刺激进入意识知觉时,屏状核是否被激活了。他没有完成,但他的思路给了后人启示,于是坎德尔完成了。这种科学家之间的传承,何尝不令人动容?
历史上那些对科学的发展做了贡献的科学家们,就如已演变成中子星但仍在浩静夜空中闪耀着光芒的恒星的“鬼”,即使已经消亡,但星光一直在照耀我们。
若我们在黑夜里寻求真理时能有一缕星光相伴,即使可能会走弯路,总比闭着眼往前走来得可靠得多。而当我们走到一片完全没有星光的黑夜之中时,我们大可以毫无顾忌的摸索前进,因为终究有一天,会有一个执着着摸索前进着的人,成为这片黑夜上的星光给之后前来探路的人照亮前路的方向。
未来,当你再次仰望星空,看到这些可能几百万年前便已逝去但仍将光辉抚在你脸上的繁星,你想到亚里士多德,想到牛顿,想到达尔文,斯人已逝,科学犹存,这也许就是科学的魅力所在。
而我们擎路蓝缕,如坎德尔继承克里克一般,头顶星光脚踏实地的不断探索先人未曾或未能触及的领域,这也许就是对继承与叛逆最好的注解。
这篇文章作于2015.04,是我与自然对话的Final paper。转眼便是八年,我也真的在做一些算是“新东西”的科研,每每再读,都思绪万千。希望自己的赤子之心不要随着时间磨灭,希望自己能真的脚踏实地,有幸也能成为漫漫黑夜中的那一束星光。