建议配合 https://www.bilibili.com/video/av56239558?from=search&seid=14406218127146760248 食用。
关于read paper:我个人觉得有两块要读(思考):一块是算法上,有什么interesting或者amazing的算法值得学习。另一块就是经验、思想上,作者是如何提出这个方法的,这个方法背后蕴藏了什么思想/经验。
Background
- RNN不利于parallelization
- Attention可以无视sequence距离挖掘信息。(我爱这个笑着眼睛像月牙弯弯每天都像阳光一样点亮我的你-> key information:我爱你)
- 如今的attention(16年)仍然是和RNN一起出现(used in conjunction with recurrent network)
- 现在的work:要么不能并行。要么可以并行(例如CNN)却不能挖掘远处关联。(我爱月牙弯弯)
- Tranformer:第一个完全利用self-attention计算input和output的representation。(不用RNN,CNN)
Include 反义词: preclude 排除,杜绝:This inherently sequential nature precludes parallelization within training examples
albeit:尽管
Model Architecture
Overview:
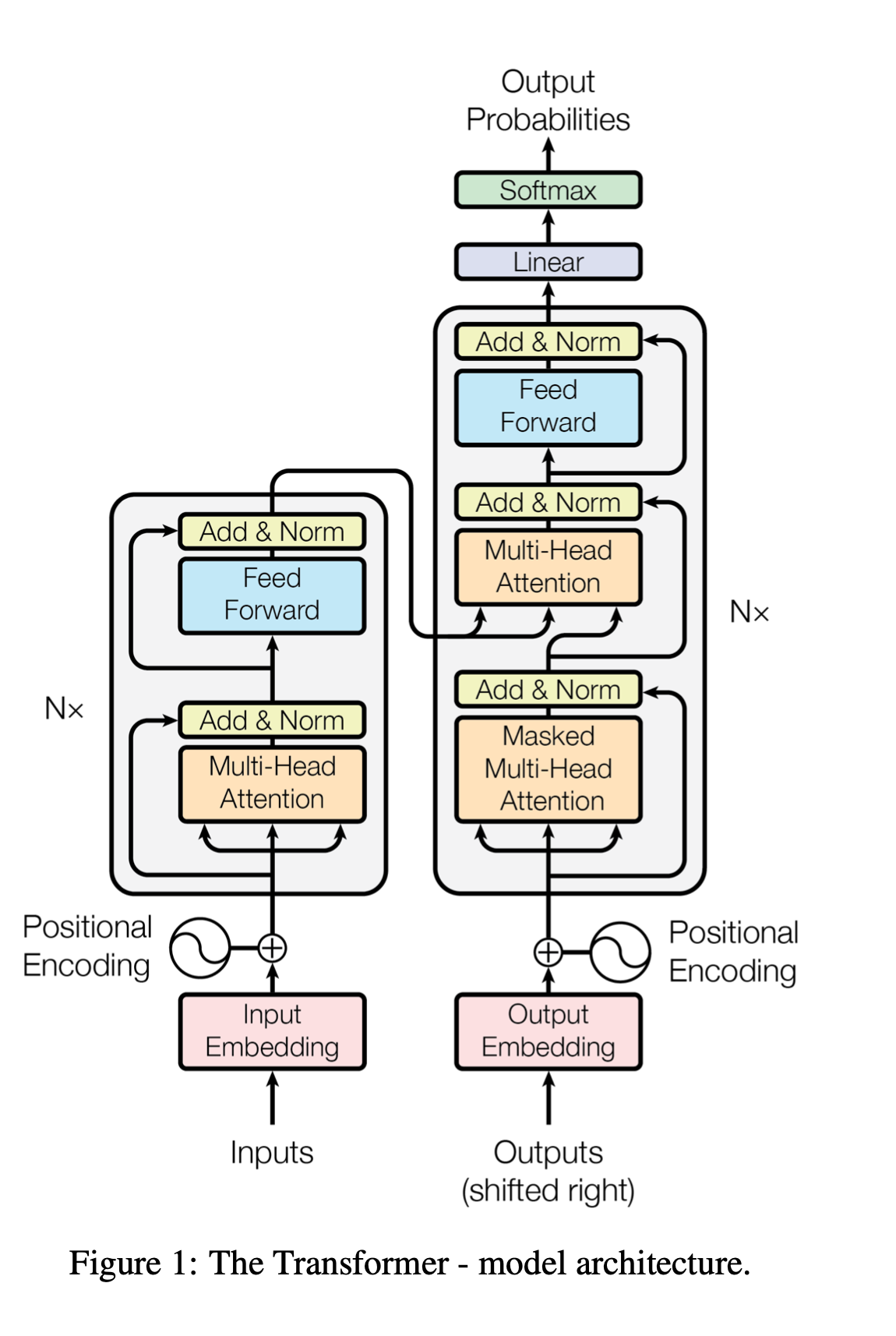
1 | At each step: (sequence to sequence should be generated step by step) |
Encoder
- LayerNorm(x + multi-head(x))
- LayerNorm(x + feedforward(x))
- keys,values,querys: input x
Decoder
Addtional sublayer compared with Encoder: Masked attention layer(ensures that the predictions for position i can depend only on the known outputs at positions less than i.)
Keys, values: middle sequence from encoder
querys: Masked multi-head attention
Self-attention
A mapping from a query and a set of key-value pairs to an output
output: a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function(适合性方程?总之就是计算相似度) of the query with the corresponding key.
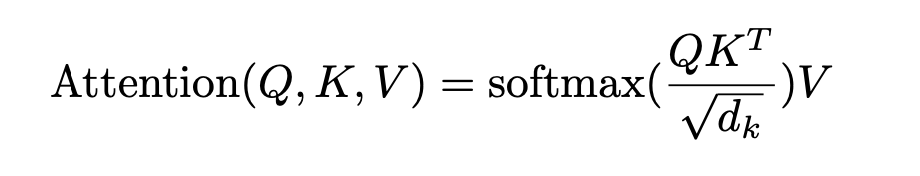
$Q: [seq,d_k], K:[seq,d_k],V:[seq,d_v]$
$seq$: sequence length
注意 原x dimension 为$d_{model}$, 经过linear projection转化为 $d_k,d_v$ dimension
Multi-head
$x:[d_{model}] => [h *d_v]=>[d_{model}] $
h:head数目。(multihead最后concat起来,所以是$h*d_v$)
再经过一次linear transform到$d_{model}$
Positional Encoding
常见的position方法就是one-hot encoding,但显然不能input dimension匹配,而且若用one-hot encoding 直接sum 未免显得太蠢。
Transformer提出了利用正余弦的方法:
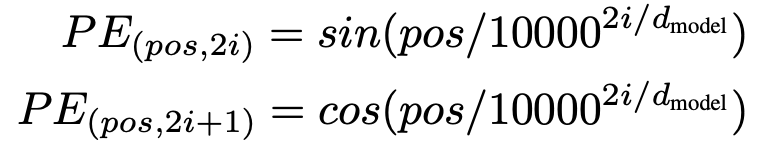
PE即为目标embedding。pos为word所处位置,2i即为 $d_{model}$中的维度之一。
- PE(:,x)即为$x_{th}$ dimensition下所有position的维度。 可以看到是一个周期函数
- PE(x,:)即为$x_{th}$ position下的embedding,是一个从波长为2pi 到 10000 * 2pi的函数。
但这里反直觉的是 PE是和input直接相加。而不是concat。。。 奇怪呢。
Dropout -> Residual -> Layer Normalization (Some papers claim that layer normalization should be in the sub-layer instead of behind residual summation)
Why self-attention
- # of operations
- Parallel
- path length between long-range dependencies in the network
Results
- Dropout 效果明显