四月的碎碎念
Forbidden area!
我是个很少看剧的人。在我看来,冗长的剧情、尤其是毫无营养又冗长的剧情、尤其是毫无营养又冗长的宫廷剧实在是浪费生命。不过我为数不多的几次看剧都是真香结尾:大学的射雕英雄传,信号真香了,这次的1988也真香了。用真香这个字眼其实也不太准确:我还是对豆瓣高评分的事物抱有期待的,毕竟自己也只是个喜好和大众口味很匹配的芸芸众生之一。
照例。写一些自己印象深刻的点。
胡同里的所有人都太温暖了,温暖到我觉得这只可能是个乌邦托。德善很想被疼爱,但是只有两个荷包蛋时还是说自己不用,虽然自己其实也很委屈。爸爸知道了德善的委屈后,也可以如朋友般的和德善坐着聊天:”德善啊,对不起,爸爸也是第一次做爸爸。。“。善宇怕妈妈担心,把妈妈做的盒饭在进门前全吃完了。阿泽在知道爸爸的想法后,坦率的支持爸爸:“我只希望爸爸能过得幸福,毕竟爸爸也有自己的人生。”。正焕知道妈妈的情绪后,故意搞砸家里的事情。。。
虽然只是乌邦托,但是发现,做一个温暖的人、细心的人是真的很好哪。这些品质可以不被外界事物影响,留在自己身上一辈子,并且可以温暖到周边的人,这不是很幸福的事吗?其实说起来,从小寄人篱下的我从前倒挺会察言观色的,说好听点就是细心体贴,不过初三过后性格实在是变得太多太大条了,开朗如娃娃鱼可以,但是娃娃鱼好歹还是个人生导师、情商拉满呢,哪像我技术也不行,情商也不够,细心也丢了。
不知道是逛虎扑知乎微博逛多了,还是自己变得现实了。
看完剧,想想自己。好像丧失了十几岁的那种喜欢,那种只想无条件对喜欢人好的喜欢,现在的自己变得很担心自己陷进爱情里,担心自己对她太好就是“舔狗”。其实想想,无条件对喜欢的人好就会是丧失自我的舔狗吗?恰恰相反,因为这些想法而丢了纯真的喜欢才是真的丧失自我,不是女方的舔狗,是“世俗”的舔狗。
什么是少年感?少年感是阿泽跟着去卫生间,还假装抽烟照顾德善的情绪。是正焕看着电影义无反顾的开车回去。是善宇的喜欢就是喜欢。很多时候,我们做出的选择是基于利益判断的,能赚钱是正收益,能提高ta对我的好感是正收益,如果付出的抵不上回报带来的数学期望,我们就不做了。但若尚为少年,怎么会考虑这么多东西?意气风发的少年是纯粹简单的。我喜欢你就是喜欢你,就是和你在一起就会很高兴,你不在就感觉要死了。所以会对你好,会吃醋,会关心你的动态,会照顾你的情绪。这些都是因为我喜欢你,也只是因为我喜欢你,如若有其他的原因,譬如希望在一起,那也变味了。
另外,还有一个也许看了这部剧的所有人都会同意的想法:爱就要大胆表现出来,命运不仅仅是偶然,是许多次要做出选择的瞬间组成的,让人讨厌的不是红绿灯,也不是时机,而是我的无数次犹豫不决。其实不仅仅是爱情,还有亲情,友情,许多东西都是如此,我爱你,所以我会表现出来,表现在方方面面,就像春天到来,你能闻到花香、听到鸟鸣,感受到舒服的阳光一样。
比起简直就是初中前我的翻版的善宇,阿泽就是我的白月光啊!那种特别喜欢的人,那种特别想成为的人。温润如玉波澜不惊的性格真是太对我胃口了(我也不知道我现在怎么就是娃娃鱼的性格)。再想想自己高三努力的样子,发现我这个人真是个一辈子下来可以变化很大的角色。
像之前提到的,他很温暖,会照顾他人的情绪,娃娃鱼生气只有自己不知道善宇谈恋爱的事时立刻跳出来说自己也不知道(虽然撒谎很拙劣)。他对于自己的喜欢很坦率简单,我喜欢德善,喜欢女人的那种喜欢。他也很真实,放弃了自己喜欢的女孩后,会流泪难过,知道对方的心意后,又很直接的吻了上去,而不是像成年人一般有这样那样现实上的顾虑:那样多累啊?他还有我最想有的一点品质:知世故而不世故。采访了很长后,没有生气,而是说很晚了,让社长和他们一起吃晚饭。
就像弹幕说正峰的一样,阿泽也是“吾辈楷模”啊。希望自己以后,也可以成为一个如他般温柔细腻、知世故而不世故,一眼看过去就是干净简单的人。
好像每个人都能从这部剧里面找到代入感一样,很多男生是正焕,是啊,青春期的男生,有几个会如阿泽善宇般直率的表白自己的心意呢。而我,肯定就是善宇了。所以从一开始就对这个男生有着先天的好感,懂事的令人心疼、会小心翼翼的照顾妈妈的想法,成绩也挺好,看着他穿白大褂的样子真有点恍惚:就好像我是医生一般。
同样也有一个院子长大的玩伴,不过自己不会表达想法的缺陷也让整个回忆没有剧里那么多友情有关的故事。有次,我和老辉看到肖华正在哭着拦着正扭打在一起的父母,我们两个只是苦笑:没有后续的行动了。我们两个也都有过类似的经历,所以苦笑,我们两个都不是那么温暖照亮他人的人,所以没有后续了。我想,如果是剧里面的任何一个少年,都会去安慰他吧。
剧看完了,其实更多的还是恍惚、难过、不舍。不仅仅是对剧,还有对剧里所代表的那段时光和感情。我已经不是中学生,甚至大学生都算不上了,学生时代的爱情和我估计也是没什么缘分了,和家人邻里也不可能有长时间的相处了,朋友好像也只有博一一个可以称为挚友。
不过也不算太糟:学生的爱情不可能了,但我还可以如少年般的去喜欢一个人。家人邻里不能长时间相处,但我也还可以做一个温暖的人,朋友有博一还不香吗,博一这样简单的人世上能碰到便算作有幸了呢!
差不多也到结尾了,写完这一通,好像也活得明白通透了一点,希望自己如自己所愿,做一个简单的少年。
三月过去了一半,整个二月,包括这已经过去的三月,都是颓颓的在宿舍度过的。这段时间每天做些什么呢?
十点多迷迷糊糊起床,玩手机到十二点,然后煮饭吃饭到了下午两点,稍微刷下虎扑知乎加写下代码,哦豁又要吃晚饭了。晚饭一过,就是各种娱乐活动了,913吃鸡,之前的剧本杀,现在的冬日计划,还有打了好几遍的三国志。。。
发现脑子这个东西还是得经常用经常转。之前划水的时候以到下午头晕的不行,但是有天强逼着自己学习写code,居然就不晕了。呵呵,我这叫做富贵病吗?
感觉不能这么浪费自己生命了,至少白天不能再手机综合征下去了。(其实颓的很大一个原因,是真的眼前这个OpenMPL的coding太过烦人,不过索性最终还是在今晚解决了,希望以后可以更有朝气的做接下来的许多许多事情。)
工作方面就是这样,说起来随着疫情的严重,intern的日期可能也需要变化,可能要推迟到下学期?不知道,但总之得尽快和老板确定。什么时候确定?等我openmpl搞定后才有底气说吧:毕竟确实划了太久水。
发现自己现在是个看得很开的人,不管是感情还是事业。有点命中有时终须有,命里无时莫强求的想法在三观里了,很多东西不太愿意投入太多的热情和希望,可能是害怕失败后的失望?不论好坏,但至少大部分事物不会让我捶胸顿足,喟然叹息,感觉也是成熟的一个小小标志吧。
最近唯一让我有点情绪的是妹妹的事。和妹妹视频,五岁的小孩子一句话不说,然后眼泪就流了出来。这么小就有了难以承受的心事,这么小就得寄人篱下 没有父母的照顾,这么小就眼泪憋不住的无声的流。看着真的揪心难受,既然选择了做父母,为什么就只管生不管养呢。不希望她重蹈我的覆辙,她这么可爱 ,这么漂亮,她值得拥有自己人生的幸福。
不过家家有本难念的经。我为我妹妹的人生叹息,我爸的人生也活得挺糟糕:生意上的不顺、女儿的身疾,都让这个中年人压着担子。哎,他的担子何尝不是我的担子呢。
今天忽然看到詹青云是12届的CU本科生,忽然惊了一下,想到自己14年入学的时候唯一报名的国辩队,没准当时她也在台上。然后觉得自己的青春这一点上挺可惜的,唯一报名的原因是确实当时只对这个有浓厚的兴趣,但是碍于懒惰,碍于一般家庭出生的短视,碍于自己的懦弱,最终还是没有去参加复试。也许参加了会有很多全新的体验、很多新的朋友、自己的思想也能系统化、逻辑化,对自己人生规划也会健全很多。
不过往者不可谏,来者犹可追。未来可能还会有这种辩论的机会(哈哈,不过就算有机会,也没有时间去准备、去充实自己了吧?),再不济,其他喜欢的东西一定要去追求一下。Follow your heart。
药效好像快到了,得睡了,晚安。Neway。前几天那个超大月亮确实很大,希望未来的某天你再看到月亮的时候,你找到了那个爱你的人。
Here, I list the pseudocode of this algorithm, I didn’t implement it since it wasn’t critical for my journal…
But If you are required to implement a DL with dynamic working stitches. Hope this piece of code helps you. :)
The basic requirement of “dynamic” is:
Given a working stitch k in each polygon, the alg construct corresponding coloring rows in the dancing links.
Note that we need exactly k working stitches instead of # <= k (Since the optimality of DL is constraint by the row order, for example, if one polygon $p$ contains three stitches, then the rows indicating $p$ at beginning should be the coloring solution without working stitch, following is the # of exactly one stitch… and so on
1 | def insert_exactly_k_stitches(k): |
如果直接用 Structure a = Structure(args), 这个loop里面的a都是一个address
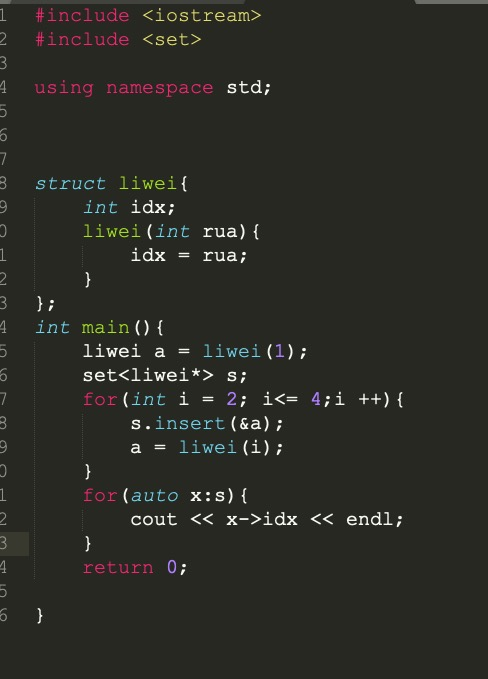
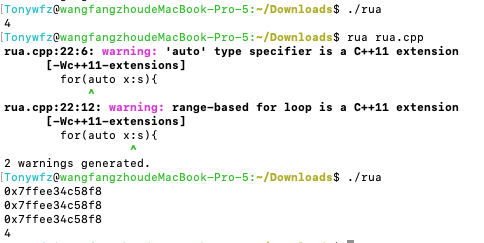
解决方法:new
1 | liwei* a = new liwei(i); |
因为openMPL 需要用Klayout处理一些gds的input 所以学了些klayout中的技巧,记录如下。
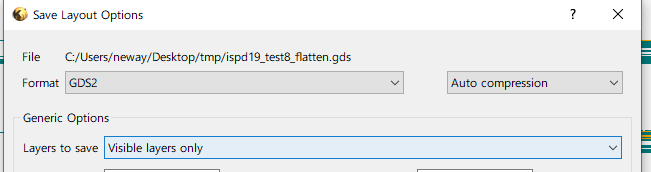
先吐槽下当代科技的gds有多大:

由Dr.CU 生成的layout 所有feature是以path形式存储的,感谢Haoyu提示klayout有直接转的方法,遂Google,方法如下
input(x).merged.output(y) 意思就是把x layer merge起来(猜测merge的这个operation就会把path及其相连的path merge成一个poly) 然后输出到 y layer。万幸Dr.CU生成的layer都是固定63,43,22可以用来decomposition(不然我一个一个点一个个放大看真的要吐)
可以看到右下角就是生成的100,101,102 layer了,这时候我们visualize三个layer (后面保存的时候可以选择只保存被visualize的layer)
layout中的feature其实是以cell为单位分布的,而cell又取自某特定library中(比如加法器就是一种cell,一个layout里面需要多个加法器)Ps:只是我现在的理解。
因此有些gds文件存储cell是以一个指向library的指针存储的(这样不用存储所有poly的各个点坐标了,只要存library中所有cell的具体信息,以及layout中cell的相对位置就可以了)。
现在的OpenMPL暂时不支持这种gds文件,因此需要把所有cell flatten,即不存指针,而是直接存指向的cell本身。
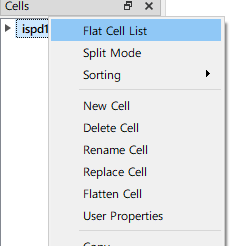
左边 右键 选中flatten cell
gds里面有许多layer用不到,我们选择性保存我们需要的100,101,102
Floorplanning is typically considered the first stage of VLSI physical design.

Placement is the process of assigning the circuit components into a chip region. (sounds similar with floorplanning?)
After placement, routing defines the precise paths for conductors that carry electrical signals on the chip layout to interconnect all pins that are electrically equivalent.

Floorplanning is typically considered the first stage of VLSI physical design.
Placement is the process of assigning the circuit components into a chip region. (sounds similar with floorplanning?)
After placement, routing defines the precise paths for conductors that carry electrical signals on the chip layout to interconnect all pins that are electrically equivalent.
用Pytorch Implement GCN的时候,有一个error卡了我一天,google也没相关的答案:
1 | fused_dropout not implemented for 'long' |
自己找了会才发现不是dropout这个value的问题,而是input feature是 long。。。原来torch.Tensor([integer])会默认给int64(Long)而不是int32.。。真是奇怪的feature呢。
1 | RuntimeError: Expected object of device type cuda but got device type cpu for argument #2 'mat2' in call to _th_mm |
data,features,model全部都cuda()了,结果还是有问题。一个小时后的思索后。本侦探再次破案:
model.cuda() 这个func应该是把所有model中的Tensor 调用一遍 cuda(),大概伪代码就是:
1 | for Var in model: |
但是问题在于!
如果Var不是Tensor 而是一个list(别问为啥会是list,菜鸡最喜欢的就是list)
那么Var.cuda()就失效了,这样就需要在initilize的时候就遍历list里面所有的tensor,并调用tensor.to(‘device’)
1 | Floating point exception (core dumped) |
网上查了下 这个就是某一步计算分母为0的error。
但是蛋疼的是 没有指示哪一行有错。而且python(或者说dgl还是pytorch)有个蛋疼的feature是这个exception在还没来得及print的时候就会直接跳出程序。(也就是说还不能用简单的print来定位)
最后用IPython embed()很蠢的一步一步。。发现问题是 如果dgl.Graph没有边(G.number_of_edges == 0),那么dgl自己的GATConv (Graph Attention Convolution会有问题),因此加了个dirty code判断这个情况,如果属实就直接生成一个zero vector(其实按道理应该是一个input feature itself,但是在这个work里面(graph color)反正没有边的图就没有利用价值,所以直接变成0)
一步一步抽丝剥茧发现:
当pytorch的unique函数为gpu版本时,最后结果居然是一个dim=-251的vec(但问题在哪并不知道)。
奇怪的是单独写一个py文件用gpu调用这个函数并没有问题,同样的input同样的设备只有放到这个project里面才会return负数dim的vec。
暂时解决方法,将调用这个函数的func(in /dgl/core.py)改到cpu上:
1 | unique_val = F.asnumpy(F.unique(sorted_val)) |