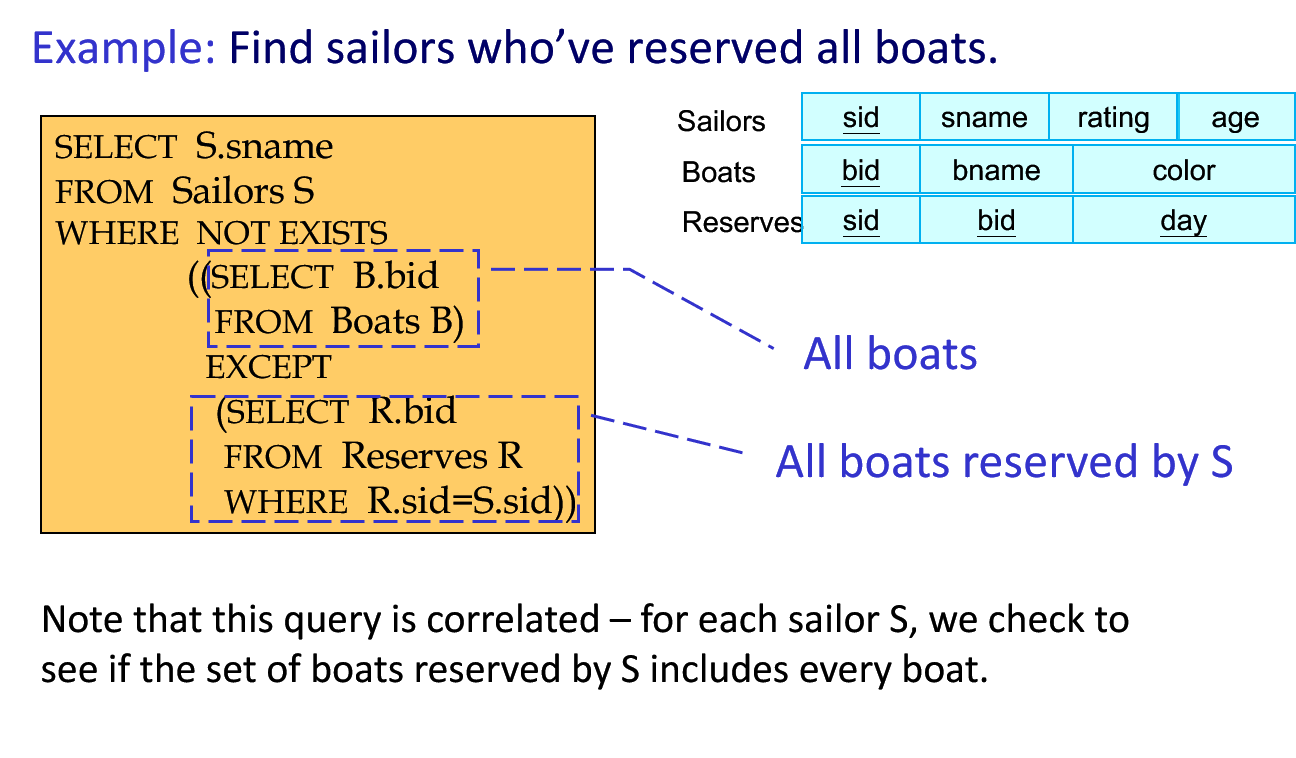
Some Terms
Ground Truth boxes: The masks labeled in the original data.
Paper writing
- Historically speaking,…
- conjecture 推测
- Qualitative results 一些example
- elucidate 阐发。make something clear
RCNN
Key contributions
proposed the impotance of features.
Features matter, the first sentence of RCNN paper.
Generalize the CNN classification results on ImageNet to object detection
BY
bridging the gap beween image classification and object detection.
Modules description
Region proposals generation: Selective search
generating category-independent region proposals. Use Selective search ( a traditional machine learning method).
1 | Input: image |
Feature extraction
Proposal transformation
- tightest square with context (context for fulfill 227,227)(context:前后关系。此处意为proposal再图像里的左右部分 )
- tightest square without context
- Resize and zero padding
Train:
- Positive data: proposals with IOU > 0.5 and Ground Truth labels
- Negative data: proposals with IOU < 0.5
A CNN model.
Input: $(227,227,3)$
Output features: $(4096)$
Class-specific linear SVMs (class independently)
For each proposal, SVM generates an expected class and corresponding confidence. Final results only include proposals with IoU (Intersection of union) [Bounding box] overlap with a higher scoring selected region larger than a learned threshold (pretty important according to the paper).
Train:
- Positive data: Ground Truth labels
- Negative data: proposals with IOU < 0.3
- Dropped data: proposals with IOU > 0.3 (Too much positive samples which do not emphasize precise localization)
Visualize method
Features
Use 10M+ images as input, for each feature unit, a output value will be generated. Then rank the 10M+ value and show images with corresponding top 10 values. (Speak for themselves)

[Each row indicates the result of each feature unit]
Ablation(切除)
- Convolution layer has sufficient representational power of image. (更偏于原图)
- Fc 更偏于 features. The fine-tuning of fc will benefit more because features of different tasks are different.(But the deep representation format of same image has no much difference)
Bounding box regression
Train
- Positive data: Region proposal with biggest IOU and IOU > 0.6. ($P_x,P_y,P_w,P_h$)
$f(P_x, P_y, P_w, P_h) = (\hat{G_x}, \hat{G_y}, \hat{G_w}, \hat{G_h})$
and
$(\hat{G_x}, \hat{G_y}, \hat{G_w}, \hat{G_h}) \approx (G_x, G_y, G_w, G_h)$
- shift. $\hat G_x = P_w d_x(P) + P_x , \text(1).\hat G_y= P_h d_y(P) + P_y , \text(2)$
- scale.$\hat G_w= P_w exp(d_w(P) ), \text(3).\hat G_h= P_h exp(d_h(P) ) , \text(4)$
- Four real parameters: $d_x(P), d_y(P), d_w(P), d_h(P) =t_*= (t_x, t_y, t_w, t_h) $
$W_* = argmin_{w_*} \sum_i^N(t_*^i - \hat w_*^T\phi_5(P^i))^2 + \lambda || \hat w_*||^2$
$t$ : real changing needing to do.
$w$: learned changing, which need to be regression.
Fast RCNN
Drawbacks of RCNN
- multi-stage pipeline trainning
- training is too expensive
- slow object detection ( proposal and the convolution forward of each proposal is the major time-consuming part )
- solved by: SPP nets(spatial pyramid pooling networks)
- computes a convolutional feature map for the entire input image instead of each proposals.
- classifies each proposal using a feature vector extracted from the shared feature map (by max-pooling to a fixed size output such as $6\times6$)
- solved by: SPP nets(spatial pyramid pooling networks)
Contributions
- Single-stage training
- No disk storage is required for feature caching
Architectures
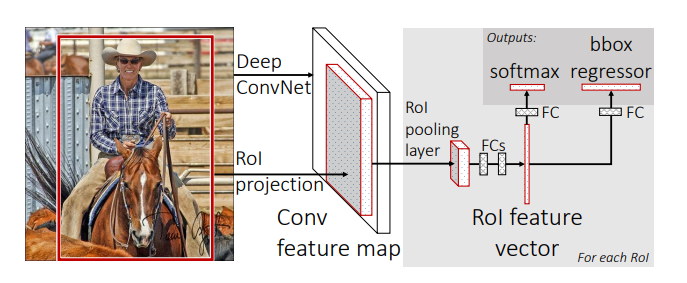
Two differences:
- feature maps are calculated using proposals, but entire image.
- Prediction of class id and bbox regression is implemented using one single network. ( instead of SVM + FC)
ROI pooling layer
Any size($16\times20$ for example ) of ROI’s corresponding feature maps will be transformed into fixed size(7*7 for example).
Using a windows of size($16/7\times20/7$) to do max pooling.
backwards calculation
derivatives are accumulated in the input of the ROI pooling layer if it is selected as MAX feature unit.
Scale invariance: to brute force or finesse?
Brute force: fixed size ( single scale)
finesses multi scale
Multi-task Loss
Overall loss = Loss of classification + bounding box regresssion
Typically, The bounding box loss is different!
$L_{bbr} = $
- $0.5x^2\ if |x|<1, where\ x =(predicted-label) $
- $|x|-0.5\ otherwise$
To avoid exploding gradient . (Previous $L_{bbr}’ = 2|x|$)
Mini batch sampling
Mini batch size = 128 = 64 RoIs /image * 2images
RoIs = 25% proposals generated AND IoU>0.5
Non Max SUPPRESSION
一组 iou > IOU_THRESHOLD 的proposals。以 iou排序, 选取最大的那个proposal, 计算其他proposals和他的iou,大于 NMS_THRESHOLD 的 全部删掉 (和最好的那个重复太多),一直重复遍历。
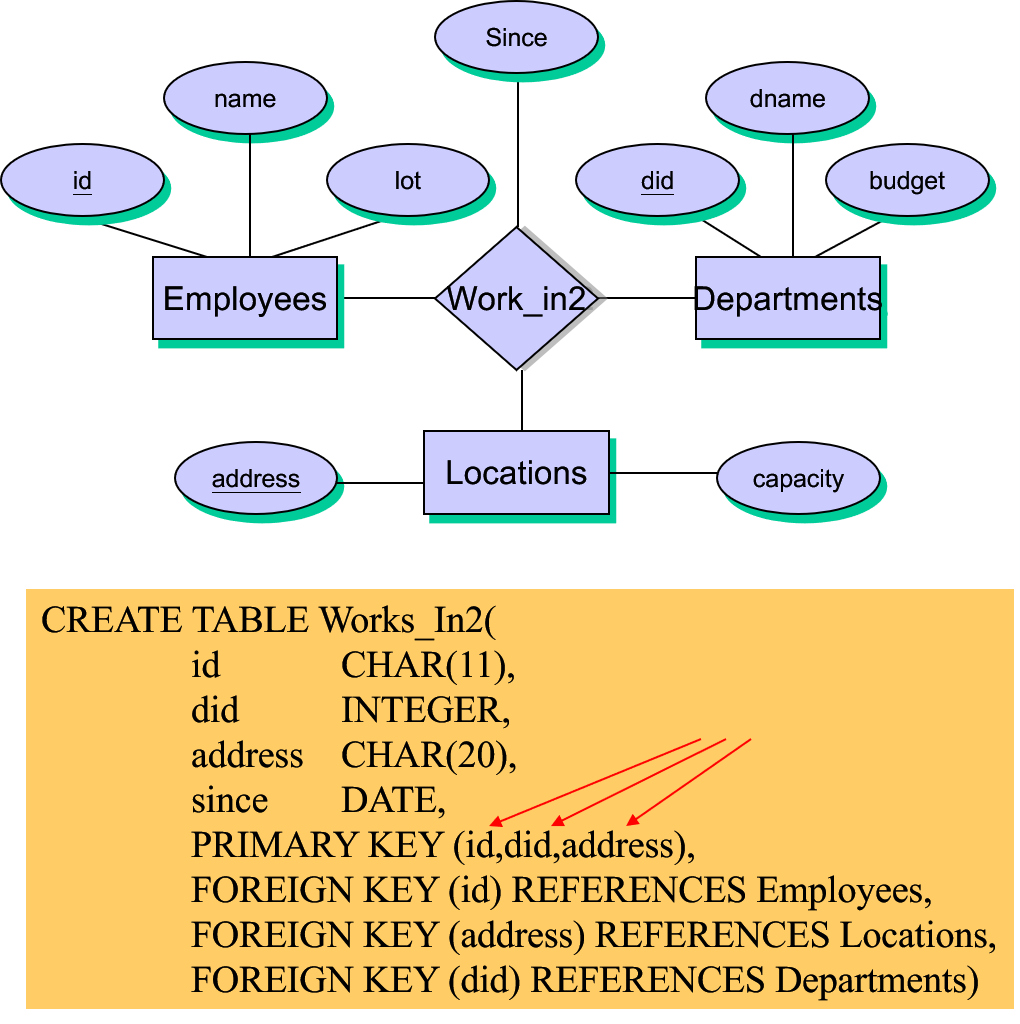
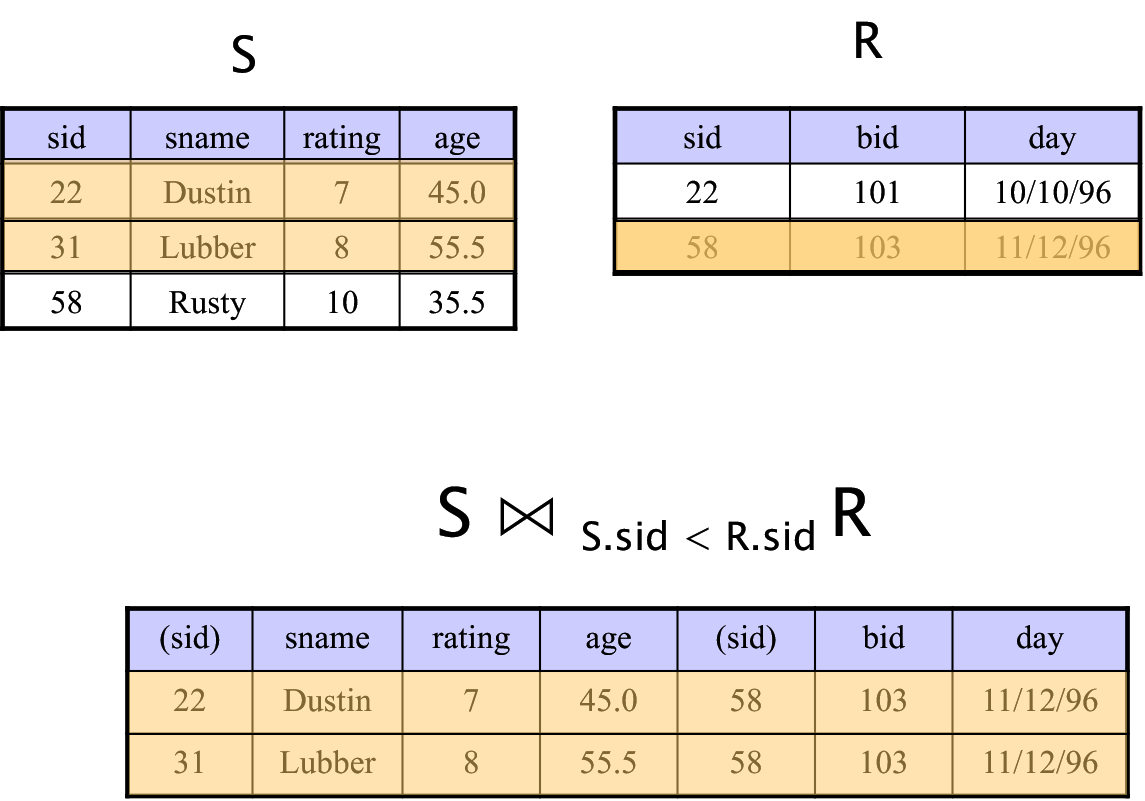
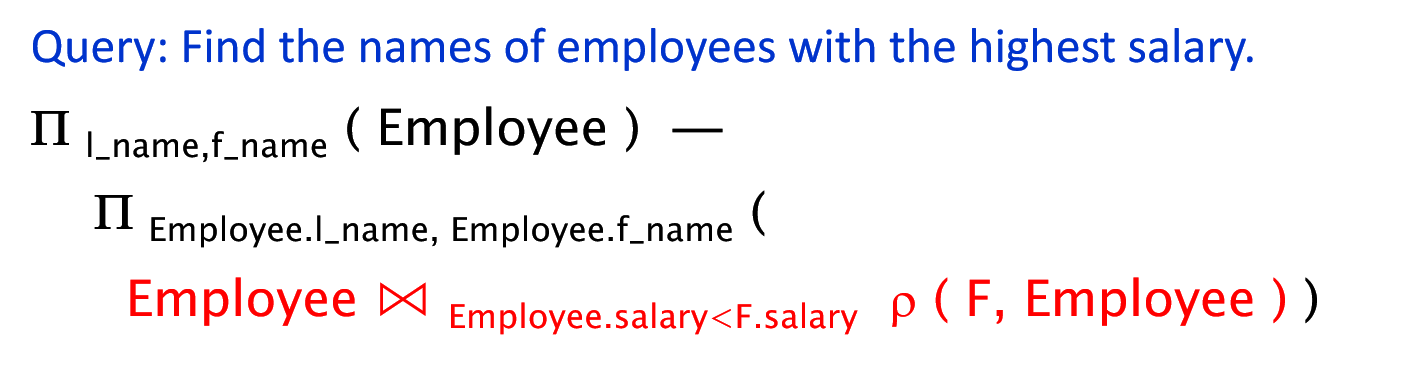
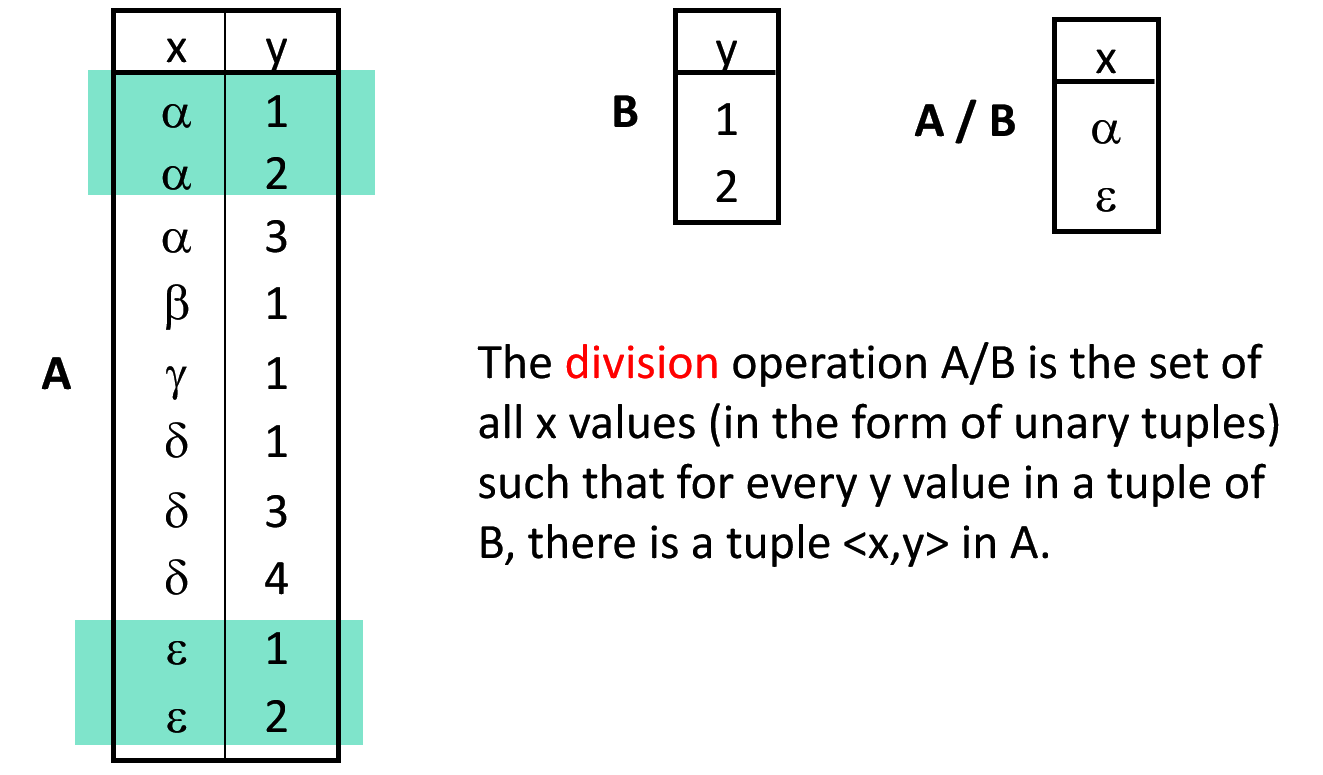
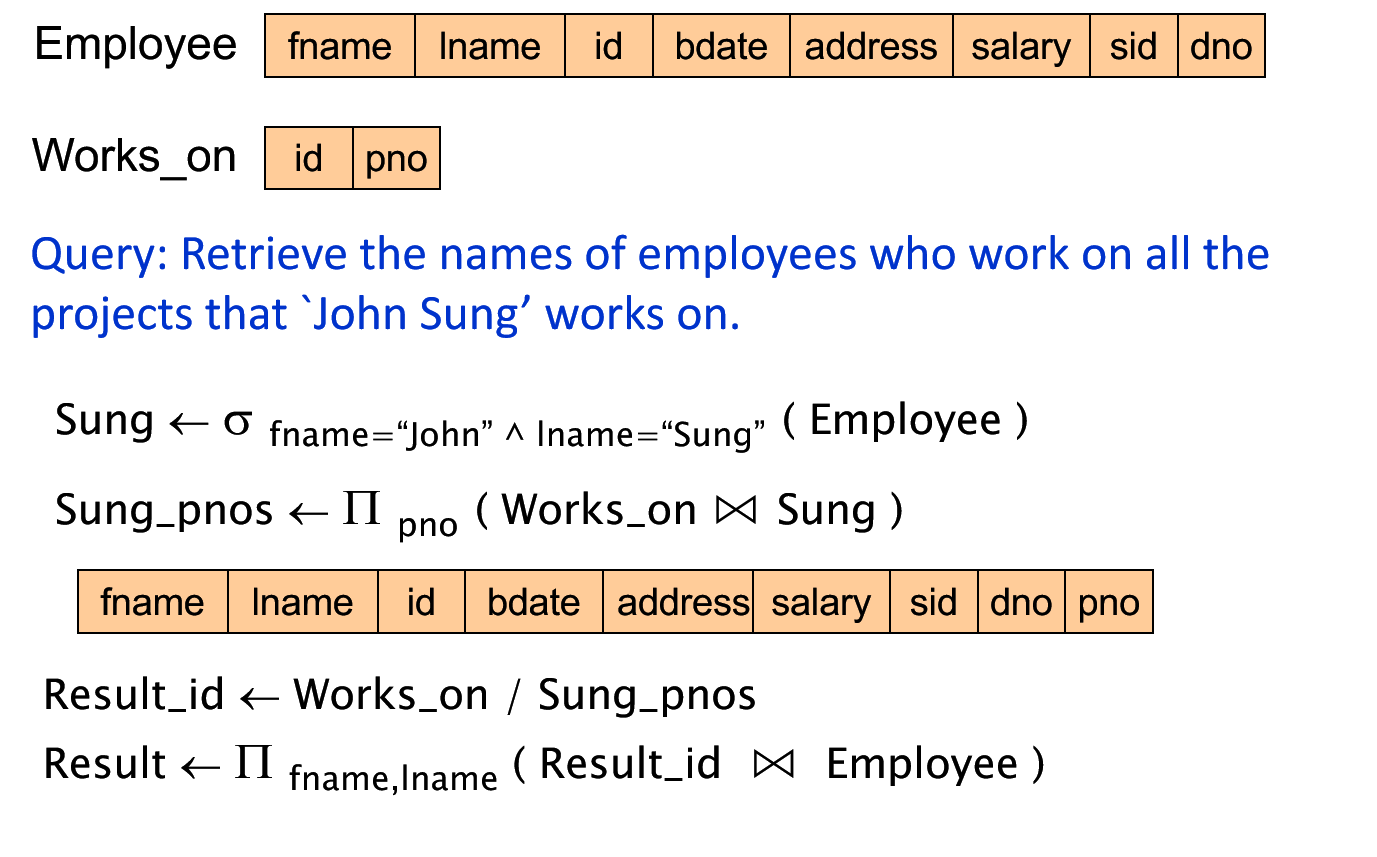



.png)
.png)
.png)