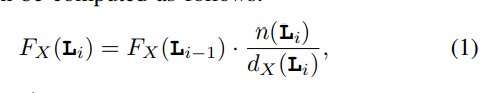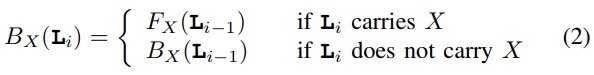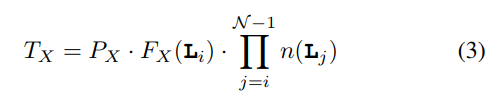difficult to simultaneously buffer the input feature maps, the output feature maps, and the filter weights in limited internal accelerator memory.
Previous method
use large SRAM buffers (up to a few MBytes may be used). drawback: large amounts of memory are not affordable.
Another point/direction:
data reuse , is determined by the dataflow schedule of computatio
Previous work: the working set of these innermost loops fits the available internal storage
drawback: existing models have not been adapted to explicitly application managed buffers, which constitute by far the most common memory architecture template for CNN accelerators, therefore, overestimate internal storage requirements
Contribution of this work:
new analytical memory performance model to evaluate dataflow schedules
best dataflow schedules
applied it on the case study of the design of a flexible CNN accelerator for deeply embedded Systems-on-Chip.
Background
Convolution loop-nest
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// M output fmaps loop LOF: for (m = 0; m < M; m++) // C input fmaps loop LIF: for (c = 0; c < C; c++) // spatial loops (ExE) LSY: for (y = 0; y < E; y++) LSX: for (x = 0; x < E; x++) // filter loops (RxR, stride S) LFY: for (k = 0; k < R; k++) LFX: for (l = 0; l < R; l++) { p = I[c][y*S+k][x*S+l]; w = W[m][c][k][l]; O[m][y][x] += p*w; }
Goal
The problem consists in minimizing the number of memory accesses to the off-accelerator memory given a limited local buffer capacity.
Reuse in convolution
Input feature maps
Output feature maps
Weight
the reuse of a reference is carried by a loop if the same memory location is used by different iterations of that loop
However, unless the entire working set fits the local buffer, this reuse cannot be taken full advantage of.
Reuse buffer
Data cache
Application-managed scratchpad memories
partitioning the local reuse buffer in a set of application-managed buffers,
considering a numpy matrix mat with shape[10,7,1,2] if we want to access the FIRST column of mat, which has shape[10] then we should use: mat[:,0,0,0] instead of: mat[:][0][0][0] (return the shape of [5]) cause mat = mat[:] actully.
Q1 why does visualizing the weights of the filters tell you what the filter is looking for?
template match. (filter = template)
the input which maximizes that activation under a norm constraint on the input is exactly when those two vectors (input + filter) matches up.
visualization of second last layers:
L2 nearest neighbors in feature space can be same types ( tree on the left or tree on the right)
visualization of middle layers
select images with maximal activations in exact channels of exact layers (the selected images are usually same)
mask part of the image before feeding into CNN
saliency maps
which pixels matter?
computer gradient of output/input directly
deep dream
set feature maps as the (backpropagation) gradient to maximize the features found by DNN
neural texture synthesis
generate a big texture from a small texture(image)
how to compute Gram Matrix(also for style transfer)?:
get a feature map through DNN with size ($C\times H\times W$)
generate $cchw$ matrix for each pair of c-dimensional vectors measuring co-occurrence ($new_{ij} = old1_iold2_j$)
average from cchw to cc
using random image to generate gram matrix and compare it with input’s gram matrix( loss function to compare)
style transfer
gram matrix is also used
but the iteration may be too large (random image as initial image), solution: train a DNN(feedforward net in the image) ,input: raw image output: style image and the weight is updated by throwing the output into the gram matrix calculation procedure.
面试的时候有说 charles kao 是自己的偶像,想做newton in physicals那样的人物。教授有点“冷笑”的意思。 再想想自己现在其实并没有什么能摆上台面的achievement,说这种话真有点“志大才疏”的意思,心比天高的人其实是我最不想成为的人。在我能说出这些话之前,先有足够的实力才不会被人质疑。不过所幸还有足够时间努力。
eric lo 从工业界回到学术圈的原因也知道了,不喜欢编程。觉得钱不是最重要的事。很高兴其实还是有很多人这么想的。就像记者问charles kao没有光纤专利后不后悔,他说不后悔,” if everything is for making money, then I cannot absolutely invent the optical fiber”。至少我也一定不会做一个money-oriented 的人,对我来说 人生的追求不是making big money.