STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORS
Motivation: Naïve pre-training strategies (graph-level multi-task supervised pre-training) can lead to negative transfer on many downstream tasks.
Pre-train Method
NODE: Context prediction:探索graph structure information
context graph: for each node, the subgraph between $r_1$-hop and $r_2$-hop.
context anchor nodes: 假设GNN是r-hop,context anchor nodes就说context graph和r-hop overlap的点。(也就是r1 到 r 之间的点)
- 获取context embedding
- 用GNN获取context graph 上的node embedding
- average embeddings of context anchor nodes to obtain a fixed-length context embedding.
- context embedding和对应的r-hop 的node embeeding的inner product接近1 (prior that the two embeddings must be similar when they come from the same neighborhood)
NODE (also applies to GRAPH level): Mask attributes and predict them
Principal Neighbourhood Aggregation for Graph Nets
单个aggregator不行,需要combine多种不同aggregator
这里的S 是基于degree的一个额外系数: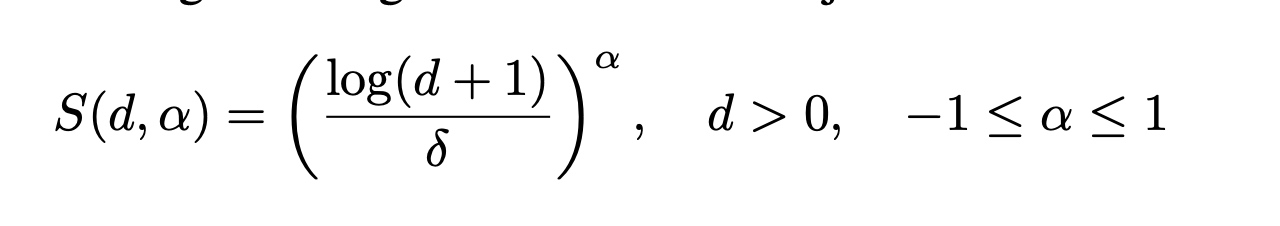
alpha pos时,node的degree(d)越大,S值就越大,于是feature值越大。(amplification)
反之则为 attenuation
Global Self-Attention as a Replacement for Graph Convolution
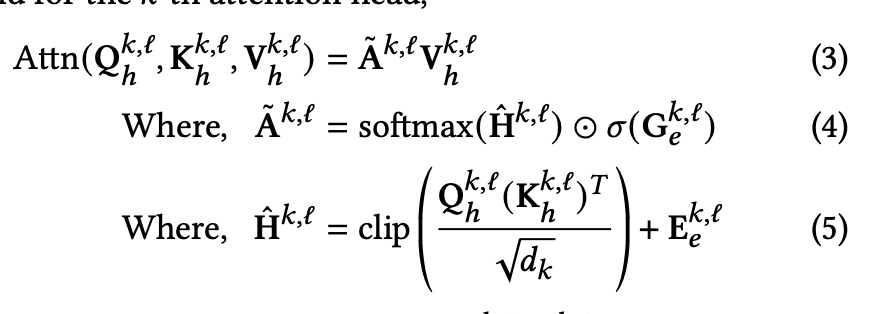
The basic idea is, rather than pre-defined functionality of edges, which introduce inductive bias. Let transformer learns it by itself.
here, edge information used in:
- $G$ is linear projection from edge embeedings. Will be a gate contriolling the attention. (Eq 4)
- $E$ is a linear projection from edge embeddings. Directly influence attention. (Eq 5)
- $E$ SVD on adj mat A, and use left and right singular vectors as positional encoding.