This is a reading notes for recipe generation papers, whcih is for my 10701 projects.
Generating Personalized Recipes from Historical User Preferences
Input:
- the tokenized name of a specific dish, (vocabulary embedding)
- a few (partial) key ingredients (ingredient embedding )
- calorie level. (caloric-level embedding)
tokenization method: Byte-Pair Encoding (BPE) tokenization
Output
tokenized recipe sequence
Approach
Input -> encoder-decoder -> attend with hiden user features (come from previous recipe ranking of this particular user) -> combine them with a attention fusion layer to jointly determine text generation
Encoder
BiGRU for dish name and ingredients
Projection for calorie level
Decoder ((output: recipe embeeding ($h_t$)))
two-layer GRU, where first layer input $h_0$ is the concatenation of the output from the encoder, for each layer, there is an attention term that calculates an weighted sum of the encoded ingredient feature
Combine with user hitorical review data
Each prior reviewed recipe has a recipe embedding, and is used to calculate the recipe attention
Each recipe has multiple used techniques and we use them to calculate the recipe
Attention Fusion Layer
fuse all contexts calculated at time t, concatenating them with decoder GRU output and previous token embedding:
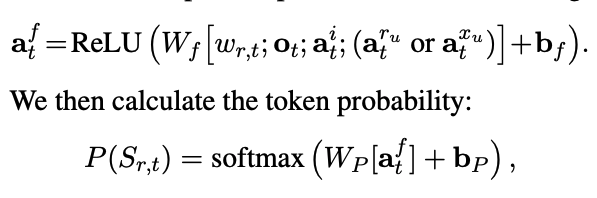
$o_t$ is the output of decoder, $a_t^i$ is the ingredion features (calculated based on weighted sum of ingredient sum), $a_t^{r_u}$ is the user recipe feature (calculated based on weighted sum of user previous ranked recipe representation)
Final output
Top k sampling means sorting by probability and zero-ing out the probabilities for anything below the k’th token. It appears to improve quality by removing the tail and making it less likely to go off topic
Experiments
Dataset
Here, we restrict to recipes with at least 3 steps, and at least 4 and no more than 20 ingredients.
We discard users with fewer than 4 reviews, giving 180K+ recipes and 700K+ reviews
in our training data, the average recipe length is 117 tokens with a maximum of 256.
Train/Test/Validation
We order reviews by timestamp, keeping the most recent review for each user as the test set, the second most recent for validation, and the remainder for training
Cooking techniques
We manually construct a list of 58 cooking techniques from 384 cooking actions collected by Bosselut et al. (2018b);
Evaluation metric
BLEU (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. each word in the output has a maxinum clip value, which is the count in the true labels.
ROUGE-L: Longest Common Subsequence (LCS)[3] based statistics
Personalization (randomly 9 user input + 1 golden user input -> output probability of word (prob of sensente ))
(UMA)—the proportion where the gold user is ranked highest—
Mean Reciprocal Rank (MRR) (Radev et al., 2002) of the gold user