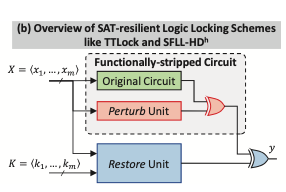
PAC learning try to study the generalization ability for a learning model (given a set of training data, its ability to carry over to new test data)
I recommend for reading this blog post (by the original author)
https://jeremykun.com/2014/01/02/probably-approximately-correct-a-formal-theory-of-learning/
Approximately correct means the error will be small on new samples,
Probably means that if we play the game over and over we’ll usually be able to get a good approximation.
Error of hypothesis $h$ (with respect to the concept (our target, the “golden” solution) $c$ and the distribution $D$ ) is the probability over $X$ drawn via $D$ that $h(X)$ and $c(X)$ differs.
concept class: a collection of concepts (functions) over $X$
PAC Learnable: A problem is PAC-learnable if there is an algorithm $A$ which will likely generate a hypothesis whose error is small for all distributions $D$ over $X$.
More formal one: small error -> error probablity = $\epsilon \in [0,0.5]$; high probability -> $1 - \delta$ : $\delta \in [0,0.5]$. Then, we limit the algorithm to run in time and space polynomial in $1/\epsilon $ and $1/\delta$
Let 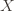 be a set, and
be a set, and 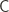 be a concept class over
be a concept class over 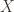 . We say that
. We say that 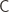 is PAC-learnable if there is an algorithm $A(\varepsilon, \delta)$ with access to a query function for and runtime $O(\textup{poly}(\frac{1}{\varepsilon}, \frac{1}{\delta}))$, such that for all
is PAC-learnable if there is an algorithm $A(\varepsilon, \delta)$ with access to a query function for and runtime $O(\textup{poly}(\frac{1}{\varepsilon}, \frac{1}{\delta}))$, such that for all 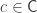 , all distributions
, all distributions 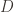 over
over 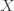 , and all inputs $\varepsilon, \delta$ between 0 and
, and all inputs $\varepsilon, \delta$ between 0 and 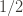 , the probability that
, the probability that 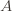 produces a hypothesis
produces a hypothesis  with error at most
with error at most  is at least
is at least 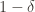 . In symbols:
. In symbols:
$\displaystyle \textup{P}{D}(\textup{P}{x \sim D}(h(x) \neq c(x)) \leq \varepsilon) \geq 1-\delta$
How to prove a problem/ a concept class is PAC learnable?
big idea:
- Propose $A$ with time complexity $O(m)$
- Show that $A \propto 1/\epsilon, 1/\delta$ , easy right? :)
Example 1 Interval Problem
The target is an interval $[a_0,b_0]$, each query (unit time cost) will randomly pick up a value $x \in [a_0,b_0]$.
We propose A: pick up $m$ samples, (therefore $O(m)$ time), and pick up the smallest one $a_1$ and the largest one $b_1$ as the predicted interval (hypothesis) $[a_1,b_1]$
We should consider $P(h(x)\neq c(x))$ (this one must be a formulation related with $m$, say $g(m)$), that is, show that if $P_D(g(m) \leq \epsilon) \geq 1- \delta$ , then $m \propto 1/\epsilon, 1/\delta$
$P(h(x)\neq c(x)) = g(m) = \textup{P}{x \sim D}(x \in A) + \textup{P}{x \sim D}(x \in B)$, where $A = [a_0,a_1], B = [b_1,b_0]$
then, by symmetry, if we can prove that $\textup{P}_{x \sim D}(x \in A) \leq 2/\epsilon$ is very probabilitic ($\geq 1-\delta$), then, we are done.
but, how to find the correlation between $\epsilon$ and $m$? The solution here is to define a interval $A’$, where $A’ = [a_0,a’]$ and $P(x\in A’) = 2/\epsilon$.
if $a’ \geq a_1$, we already finish the proof.
Othersiwe, the probability that the sample does not belong to $A$ (remeber that we are considering $\textup{P}{x \sim D}(x \in A) \leq 2/\epsilon$) is smaller than $1- 2/\epsilon$, i.e., $\textup{P}{x \sim D}(x \ not \in A) \leq 1 - 2/\epsilon$
then the probability that all $m$ samples does not locate in $A$ Is: $\leq (1 - 2/\epsilon)^m$
Note that this probability equals to the probability that the error ($h(x) \neq c(x)$) due to the $A$ region is larger than $2/\epsilon$ (the probability that our chosen 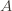 contributes error greater than
contributes error greater than  )
)
Such a proof holds for B region. Since A and B are not intersected, we can conclude that
The probabity that the error is larger than $\epsilon$ is less than $2((1 - 2/\epsilon)^m)$
it means, The probabity that the error is less or equal than $\epsilon$ is larger than $1 - 2((1 - 2/\epsilon)^m)$
We want the probability of a small error is larger than $1-\delta$, that is:
$\displaystyle 2(1 - \varepsilon / 2)^m \leq \delta$
therefore, $m \geq (2 / \varepsilon \log (2 / \delta))$
(which is polynomial in $1/\epsilon, 1/\delta$)Therefore, we finish the proof
Example 2 hypotheses/concepts in a finite hypothesis space
The theorem is:
Let H be a finite hypothesis space. Let D be an arbitrary, fixed unknown probability distribution over X and let c ∗ be an arbitrary unknown target function. For any �, δ > 0, if we draw a sample from D of size 
then with probability at least 1 − δ, all hypotheses/concepts in H with error ≥ �$\epsilon$ are inconsistent with the sampled data
(with probability at least 1−δ any hypothesis consistent with the sampled data will have error at most �$\epsilon$)
Proof:
- Consider some specific “bad” hypothesis $h$ whose error is at least �$\epsilon$, then the probability that $h$ is consistent with the sampled data is at most $(1-\epsilon)^m$
- There is at most $|H|$ bad hypothesis.
- the probabilty that there exists a bad hypothesis that is consistent with all sampled data is at most $|H|(1-\epsilon)^m$ (union)
- the probabilty at the third step should also be at most $\delta$ by definition
- That is, $|H|(1-\epsilon)^m < \delta$
- Using the inequality 1 − x ≤$e^{-x}$, we get the equation in the theorem
Relationship between observed error rate and true error rate
In Non-realizable case (more general case), there may not be a “golden solution”, we can only compete with the best function (the function of smallest true error rate) in some concept class H. A natural hope is that picking a concept c with a small observed error rate gives us small true error rate. It is therefore useful to find a relationship between observed error rate for a sample and the true error rate.
Hoeffding Bound
Consider a hypothesis with true error rate p (for example, a coin of bias p) observed on $m$ examples (the coin is flipped m times). Let S be the number of observed errors (the number of heads seen) so S/m is the observed error rate.
Hoeffding bounds state that for any � $\epsilon$ ∈ [0, 1]

The relationship result by hoeffding bound
Let H be a finite hypothesis space. Let D be an arbitrary, fixed unknown probability distribution over X and let c ∗ be an arbitrary unknown target function. For any �$\epsilon$, δ > 0, if we draw a sample S from D of size
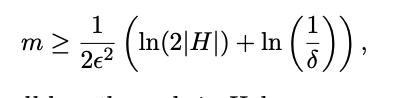
then probability at least (1 − δ), all hypotheses h in H have
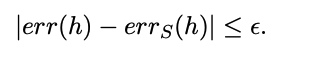
Proof: given a hypothesis h, by hoeffding boundinhg, we get that the probability that its observed error outside $\epsilon$� of its true error is at most

(based on hoeffding boudning, and the definition of $m$)
By union bound over all all h in H, we then get the desired result.
Infinite hophothesis set?
union bound is too loose! There may be many overlap between two hypothesises. That is, two hypothesises may label most data points the same.
Some definitions
VC bound (relationship between data size and errors)

If no golden target:

VC dimension (the complexity of the hyphothesis set)
$d_{VC}(H) = $ the largest value of $m$ s.t. $g_H(m) = 2^m$, i.e., the greatest number of data points that can be shattered by $H$
For example, for a N-dimensional linear seperator, its VC dimension is $D+1$
Statistical Learning Style bounds, (fixed data size,relationships between the true error and the data error)


Agnostic case: trainning error is not zero
traning error decreases as VC dim increases (easier to )
the bound increases as VC dim increases (harder to generalize)

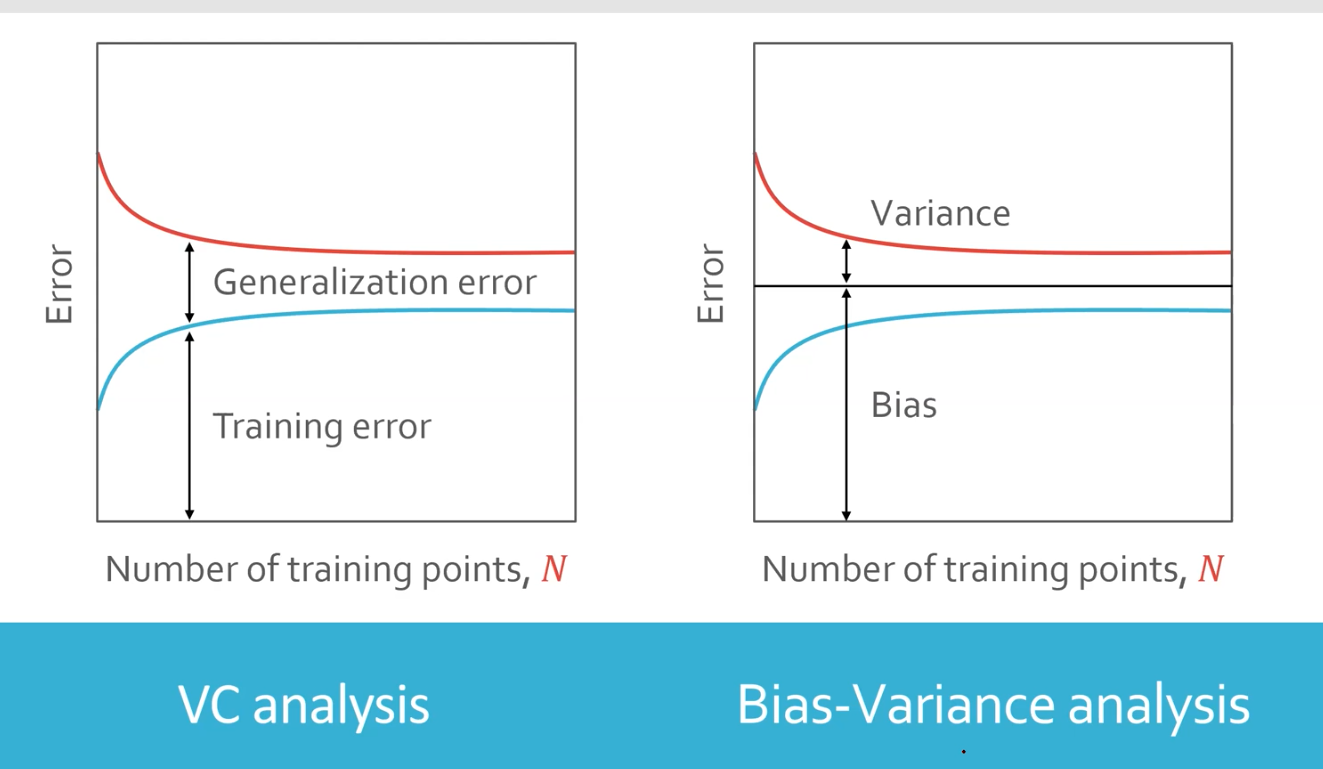
Two analysis illustration (VC analysis and bias-variance)