知道DEFT被DAC拒了后,化悲愤为动力,作此文
P.S. 什么样的结局。才配得上这一路颠沛流离。。。以后起标题建议用FAKER,MJ 之类的名字。
自从大模型之后,这样的技术博客逐渐丧失了它的原本意义。Gemini总结的比我好多了,你甚至可以让它给你写一份给洗脚城大爷科普的文章。之所以还要在这记下我的一些拙见,主要还是一个inspire的作用 - 也许有人读了这文章后发现这玩意有点意思,有点启发呢。至少对我来说,这对differentiable programming很重要。(at least Gemini is a passive chatbot now)
当我们需要优化多个任务,而这些任务很多时候conflict的时候,理论上我们直接取gradient平均值就好了。但是当landscape曲率过大的时候,这种step更新的backpropagation就会导致一个问题 - 高估了我沿着dominating task走的benefit,低估了给dominated task带来的伤害。(cite: Gradient Surgery for Multi-Task Learning)
那么我们有请解决这个问题的选手们入场
- PCGrad (Gradient Surgery for Multi-Task Learning)
这位选手指出 把所有task的gradient 都project到和他conflict的task的gradient的normal plane上,这样就没有conflict了!大概如下: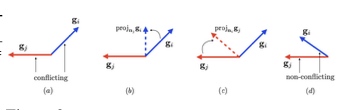
- FAMO: Fast Adaptive Multitask Optimization
这位选手指出,我们使所有任务在对数空间下的下降速率对齐。(这个背景是表达有一些任务被under-optimized了)
它维护一个辅助变量 $z_i$(可以看作是权重的 logit 值),根据 Loss 的变化进行更新:
$$z_i^{(t)} = z_i^{(t-1)} + \gamma \left( \log L_i(\theta_t) - \log L_i(\theta_{t-1}) \right)$$
直观理解: > * 如果任务 $i$ 的 Loss 在这一步上升了(或者下降得比别人慢),$\log L_i$ 的变化量就是正的或者较大的。这会导致 $z_i$ 增大,从而在下一步中增加该任务的权重。
- Nash-MTL:
将多任务优化看作一个纳什议价问题(Nash Bargaining Problem)。它的出发点非常硬核:不再强行投影梯度,而是让各个任务通过“谈判”达成一个大家都满意的更新方向。核心逻辑想象 $K$ 个任务在分一块名为“参数更新”的蛋糕。每个任务都希望梯度更新方向 $\Delta \theta$ 尽可能靠近自己的梯度 $g_i$。Nash-MTL 寻找一个方向,使得所有任务获得的改善(Utility)的乘积最大化。其目标函数定义为:
$$\max_{\Delta \theta} \prod_{i=1}^K \langle g_i, \Delta \theta \rangle \quad \text{s.t.} \quad |\Delta \theta| \le \epsilon$$
转换为对数形式后,这等价于:$$\max \sum_{i=1}^K \log(\langle g_i, \Delta \theta \rangle)$$
为什么它比 PCGrad 高级?尺度不变性 (Scale Invariance): 这是 Nash-MTL 最杀手锏的特性。即便任务 A 的梯度量级是任务 B 的 1000 倍,在对数空间下,这种量级差异被消解了。这完美解决了你之前提到的“大梯度主导平均梯度”的问题。帕累托最优保证: 数学上可以证明,纳什议价解必然落在帕累托前沿(Pareto Front)上,这意味着在这个方向下,不损害其他任务就无法进一步提升某个任务。解法: 在实际实现中,它通过求解对偶问题,将 $\Delta \theta$ 写成各任务梯度的加权和 $g = \sum \alpha_i g_i$,并动态迭代计算权重 $\alpha_i$。
我发现Gemini比我总结的好多了。。。
Hint - 可以发现这些work 他们想要解决的multi-task的issue都是不一样的(虽然都是解决Multi-task问题)。对应到我们concern的问题上,可以发现ML community关注的点是所有任务都要雨露均沾(fairness),他们的底层假设都是 “共赢” (Collaboration),但你的任务真的是这样的么?